
Many viral ChatGPT examples involve testing on the training set. In the quoted tweet it writes a decent review, but it's been trained on ~5,000 papers that cite/discuss this paper. I asked it for a review *without* giving it the text and it hit most of the points in the original.
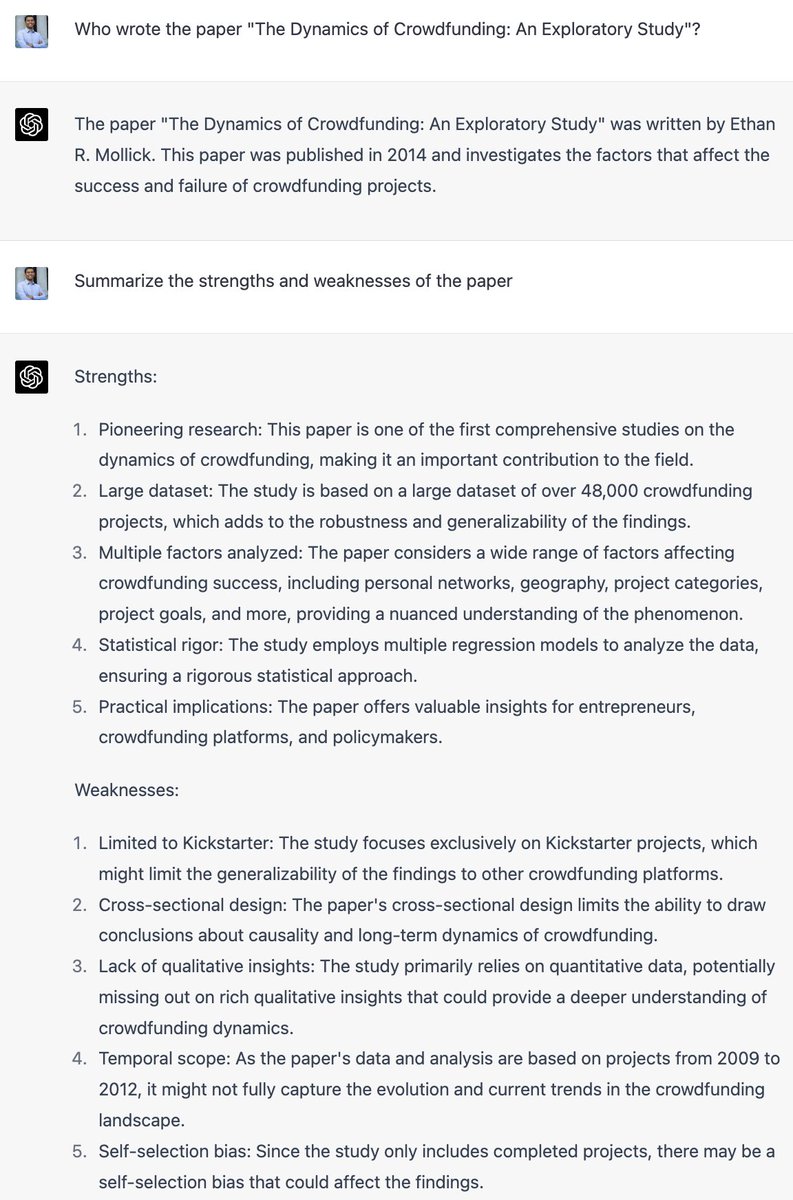
This is not to say that GPT-4 can't analyze a paper; just that this is not the way to test it. I'd love to see a rigorous study. While we're trading anecdata, @msalganik tried to use it for a review of a *new* paper and found that it didn't help at all. https://freedom-to-tinker.com/...
For the same reason, I suspect that a lot of the headline-grabbing results about GPT-4's performance on standardized exams may be misleading. https://x.com/cHHillee/status/...
Even if it hasn't seen a specific question, it seems to rely far more on memorization and pattern matching than a person would, as @MelMitchell1 showed. https://aiguide.substack.com/p... So "ChatGPT passed the bar" type claims are meaningless and misleading. https://x.com/Abebab/status/16...
OpenAI's test for whether GPT-4's training data included test questions is highly superficial — exact substring match. If names or numbers in the question were changed, or one space after a period were replaced by two, contamination won't be detected. https://cdn.openai.com/papers/...

@random_walker I actually disagree that the negative feedback is anywhere near the correctness or quality of the feedback it gave from analyzing the text. In fact, some of this example you gave is hallucinated. But points 2-4 are just wrong, and not in the review I got from pasting in text.
@emollick I completely agree that this isn't a good review; the point is that it has a lot of baked-in knowledge of others' discussion of your paper and therefore a review of a famous paper is completely uninformative about its ability to review a new paper.
@random_walker Honest question: How much training data leakage can there be if the GPT models can be run on a fraction of the memory required to store the internet?
@ATabarrok Of course, it can't memorize the entire training set, which is why it's significant that this paper has ~5K citations. It's quite possible that it has "memorized" a handful of the main themes in the paragraphs that cite this paper.
@random_walker @Meaningness obvious follow-up question: was it a fresh session? also, can we have both versions for comparison? finally, try with a fresh paper.
@lumpenspace @Meaningness Yes, fresh session. Not sure what you mean by both versions. I'm comparing it to the quoted tweet. I didn't try giving it the text of the paper.
@random_walker How are we to test it for training data leakage if we don’t know exactly what it has been trained on? Especially when models will move to more real-time training?
@random_walker Still, that means LLMs are already a better aggregation of human knowledge than search engines.
@random_walker @WholeMarsBlog Mind blowing
@random_walker Ah, great point. It's still incredibly useful, obviously. But it pushes my PASTA timelines a little farther out. (PASTA = Process for Automating Scientific and Technological Advancement, a useful meme)
@random_walker I tried using it as a tool to find a specific set of papers and a lot of the stuff was hallucinated. It even cited things that dont exist , or at least I couldn’t find them anywhere. Most of the points were technical enough that it might have fooled people on a cursory look.
@random_walker This would help explain the abysmal AP Language and Composition performance. Seemed very strange how it could so poorly analyze provided writing in that test and still be a good peer reviewer for a novel paper
@random_walker The quoted tweet and most other similar ones have only one aim and purpose: to get the most mentions on Twitter and grow their followers/brand. Over the last year, there's been a huge growth in these kinds of tweeters "8 ways to do this" "You would be shocked" "Here's what I did"
@random_walker Appreciate this point! I think the general class of issues with test/train split breaking down in the "web-scale" / "scrape everything" / "foundation model" era are really interesting and haven't been highlighted nearly enough.
@random_walker Curious, how you produce #altText?
@random_walker GPT 4 had the content and understanding of my completely novel 0 citation paper. Quite surprising
@random_walker Wow, who'd have thought Ethan Mollick was a grifter.
@random_walker Why would relying "more on memorization and pattern matching than a person would" make its ability to pass a wide range of standardized tests (at high %ile) "meaningless and misleading"? Did somebody claim GPT-4 derived answers from first principles? https://x.com/random_walker/st...