
Running list of conjectures about neural networks 📜:
- It's possible to directly patch behaviors from a pretrained neural net into a freshly-initialized network that has a different architecture.
- It's possible to convert a transformer into a nearly-equivalent RNN + fast weights, with only a modest increase in dimension.
- Softmax attention (or any other exponential similarly function) emulates the pattern separation of sparse representations within dense networks. Once sparse hardware becomes popular, this will be less necessary.
- The "linear representation hypothesis"—that neural networks compute features and represent them linearly—is false in general. But an amended hypothesis, substituting linearity with multilinearity, holds true much more robustly.
- Long-context attention heads mostly look up named entities & other highly specific concepts, to pull in their previously-mentioned associations. Occasionally they do a coarse pooling of semantic information, like "What was the overall topic of that paragraph?"
- The *correct* way to convert a multiheaded attention (MHA) layer to multiquery attention (MQA) involves contracting W_q*W_k^t (and likewise with W_o*W_v), doing some truncated SVD shenanigans, and then using the resulting matrices as your initialization for a bit of fine-tuning
Transformers can be programmed manually in a way similar to vector symbolic architectures. Something like: initialize the attention heads to build up local n-gram pattern embeddings, & store desired conditional response patterns as nearly-orthogonal vectors in the MLP weights
(continued) i.e. convert a finite state automaton definition to transformer weights: attention layer constructs a "state" from previous context, current token is the "input", and MLP stores the automaton transitions as key-value pairs like (state+input superposition, output)
Previous-token heads (and other routing circuits) in transformers can be engineered by taking the intended attention matrix and doing SVD/tensor factorization stuff to back out a set of QK weights and absolute positional embeddings that replicate that attention pattern
The low rank of transformer W_q * W_k weights, relative to higher rank elsewhere in the network, creates "noise" in similarity comparisons that is reflected in the attention logits that get computed. The exponential in softmax acts to suppress this noise
Shallow transformers can be manually constructed that use induction heads to pattern-match tokenized states + inputs against tokenized instructions, allowing it to act as the finite state machine of a (universal) stored-program computer
In 2033, people will think it extremely wasteful that different folks used to train big neural networks from scratch on the same web datasets, rather than building new networks out of circuits harvested from old checkpoints or directly synthesized in a purpose-built way
Today's LLMs spend a bunch of capacity in early layers forming n-gram/skip-gram embeddings & trying to prevent superposition interference between them. Shallower models are possible if we more explicitly encode n-grams/skip-grams
Should've put this in the thread https://x.com/CFGeek/status/16...
The above mechanism, where each attention head applies a unique rotation to the info it transfers, allows features to be distinguished / "bound". One direction can correspond to "this token = cat" while "previous token = cat" gets an ~orthogonal direction https://en.m.wikipedia.org/wik...
Potential experiment to see if transformer outlier features can be prevented by letting the network directly control (the logarithm of) divisive normalization: https://x.com/CFGeek/status/16...
Speeding up in-context retrieval: https://x.com/CFGeek/status/17...
Layers from different language models can be stitched together without finetuning (provided they share a tokenizer) by fitting sparse autoencoders to each and then running a matching algorithm between their sparse feature sets.
A neural network, just like any other signal processing system, is optimized to couple its internal dynamics (and/or its readout axes) to task-relevant axes of variation in its inputs, and to suppress or factor out (by projecting off-manifold) task-irrelevant ones.
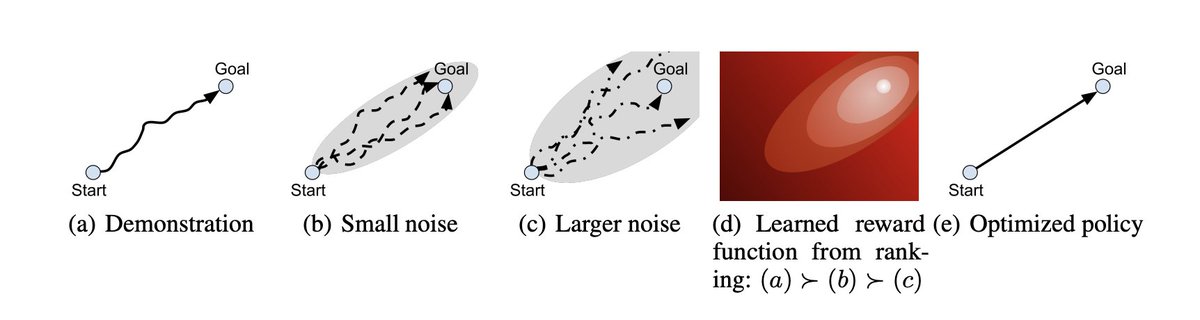
We can extract more from supervised trajectories, if we have a model that can make useful mistakes. Just take ground truth trajectories and "corrupt" them by asking an instruction-following model to introduce a specified error type. Then use those (GT, corrupted) pairs for DPO/RL
Robustly removing knowledge, skills, and abilities from neural networks—rather than just averting/disconnecting them—requires adversarial training. Otherwise the trace of the memory representation will remain, distributed within the network. Related: https://en.m.wikipedia.org/wik...
Without access to the training details (specifically the examples/episodes and their ordering), if someone hands you a bunch of Llama2-shaped weights, it is not possible to tell whether those weights produce a model that has a "backdooring" token prefix.
EDIT: I should've said, not possible to *efficiently* tell that it *does not* have such a backdoor
We can train models on tiny datasets with this trick, where we use other models/tools to augment our training data with additional datapoints inferred from the original dataset + relevant background knowledge. https://x.com/afeyzaakyurek/st...
The apparent randomness of routing within mixture-of-experts models is a feature, not a bug. You need "pattern separation" if you want to minimize interference between similar observations made in different contexts with different implications.
For linear transformers, it is possible to consolidate in-context memories into generalized/permanent memories, by taking "fast weights" (the key-value outer products) and distilling them into "slow weights" (feed-forward MLP weights).
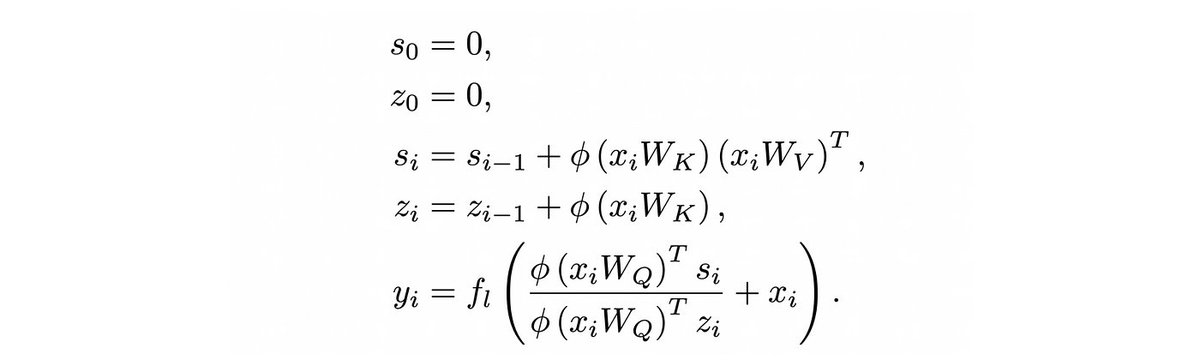
Multimodal models will stop being so bad at visual counting if we have them imitate how humans count: - A parallel system for exactly counting small # of items - A parallel system for approximately counting many items - A serial system for exactly counting unboundedly-many items
In artificial recurrent neural networks (or state space models) that are trained on tasks requiring delayed/timed outputs, we will observe internal preparatory activity along output-null directions of the hidden activations: https://x.com/NatRevNeurosci/s...
Unlike ordinary RNNs, with diagonal linear SSMs it’s possible to directly ensure stability in the forward pass and control how quickly gradients vanish in the backward pass. The same can be achieved in non-diagonal RNNs, via spectral parametrization of their recurrent weights.
Neural sequence models would benefit from special embeddings/tokens to explicitly distinguish between P(y | x), which is for a prediction conditioned on an observation, and P(y | do(x)), which is for a prediction conditioned on a causal intervention.