
For a fixed size array of objects, you can maintain two arrays of pointers to keep track of active/free ones. Seems a bit easier (and more efficient?) than a linked list and is always O(1) unlike a scan through the objects array. Does this pattern have a name?
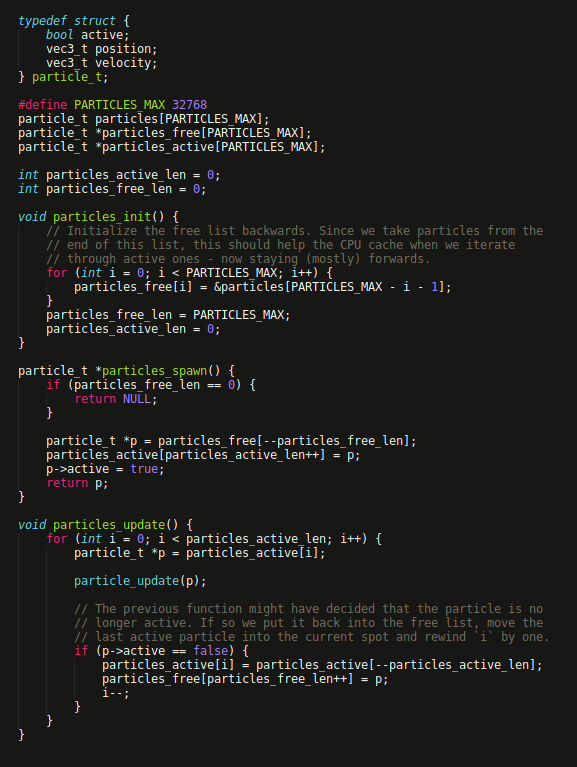
Without measuring it, I assume this only makes sense when you have a lot of objects. E.g. Quake3 has a max of 1024 entities and just does a full scan to find a free one: #L375-L434 class="text-blue-500 hover:underline" target="_blank" rel="noopener noreferrer">https://github.com/id-Software...
@phoboslab I might have missed something, but I don't think you need the double array. With the trick of always filling the empty slot with the last particle, last particle + 1 is the index to your next free particle.
@stephc_int13 Good point! For this to work, I need to actually put the ptr of the freed entity at last+1 (i.e. swap with current spot) as @simon_frankau suggested. Or just use the original objects array and copy the whole object on free (instead of just a ptr). I should benchmark these!
@phoboslab Some other approaches to also consider, because your lists do have some drawbacks: Bitset: If your objects are fixed in size and the maximum number is known, you can maintain a bitset where each bit represents whether a corresponding object is active or free. Dramatically
@dragosr particles_free[] is used as a stack in my example. How else would you implement a stack? Bitsets are certainly nice for some problems, but won't help here with efficient iteration over active particles.
@phoboslab I don’t know what it is called, but I think it is a useful pattern. For things that gets updated often, it is likely more efficient to do swap-with-last (cache coherency). But I think an advantage of this one is that pointers to the objects stay the same, which sometimes matters
@Mattias_G I wonder at what object size a swap-with-last in the storage array becomes slower than maintaining the index list. With this toy example it surely will be faster!
@phoboslab Nobody likes linked lists any more, but youre just describing a pool, no?
@soylentgraham I'm describing a specific implementation of an object pool.
@phoboslab Basically a set no? Those are also O(1)
@Sneakyness Well yes, but this is a bit more specialized. Sets are usually implemented with hashes or trees and require quite a bit more code.
@phoboslab Seems similar to https://research.swtch.com/spa...
@phoboslab if you were to unionize the particle structure with a linked list node to a next particle, then maintain an intrusive linked list out of the free particles, you would need only a pointer to the first free node and no extra array, as with a free list allocator.
@phoboslab You still have pointer indirection which kind of negates the benefits of having an array underneath (can't do data oriented, SIMD stuff). What you've built is a form of a 'cursor list' - should be in Cormen or wiki somewhere.
@phoboslab So I think this is another version for your benchmarks, with error checks and removes the cache blowout loop, to make deactivation/deletion O(1) along with O(1) initialization/addition, and access: #include <iostream> class Particle { public: vec3_t position; // position of
@phoboslab It's really a piece of ECS. I call it free list. It's more efficient if instead you store handles instead of ptrs. And instead store all positions in an array. All vels in an array. Active bits can be compressed on a single bit array of 64 bit uints. Struct of arrays.
@phoboslab Thinking about this, I think a fun optimisation is to use opposite ends of the same array for allocated and freed entries. Allocation is just increase the in-use counter. Deallocation is swap the freed entry for last in-use entry and decrease counter.
@phoboslab You don't need full 64 bit pointers for this, save your cache
@phoboslab Pretty sure this is called a “sparse set” which is a little different from a normal set!
@phoboslab If you not need preserve order, remove any item copy the last one and always add the last
@phoboslab I call this a freelist. That’s what I use for my GPU particle system too. Useful to spawn and kill in O(1) and in parallel.
@phoboslab I think that's an Object Pool (which have many minor variations of implementation). I personally prefer swap-and-pop, if element order doesn't matter, or, if lifespan of objects is consistent, a ring buffer / circular buffer.
@phoboslab I'm in love with your clean code