
What makes CLIP work? The contrast with negatives via softmax? The more negatives, the better -> large batch-size? We'll answer "no" to both in our ICCV oral🤓 By introducing SigLIP, a simpler CLIP that also works better and is more scalable, we can study the extremes. Hop in🧶

Perhaps surprisingly, we can replace the SoftMax-xent by a Sigmoid-xent loss in CLIP training and things just work. With one little detail: add a learnable bias, much like the temperature. This is conceptually simpler and cleaner: does image I and text T match: yes or no?

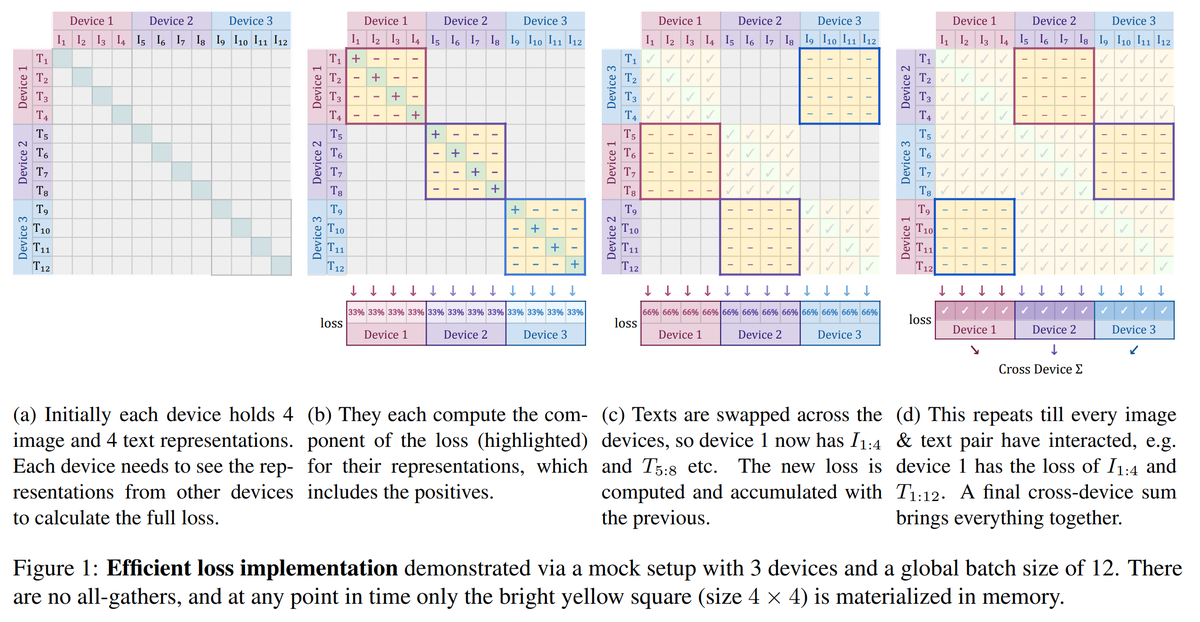
It's also much simpler code, and since every element in the similarity matrix is independent, makes it obvious that we can compute the loss "in chunks" across devices. Chunked sigmoid loss never instantiates the full all-to-all matrix, hence letting us scale batch-size.
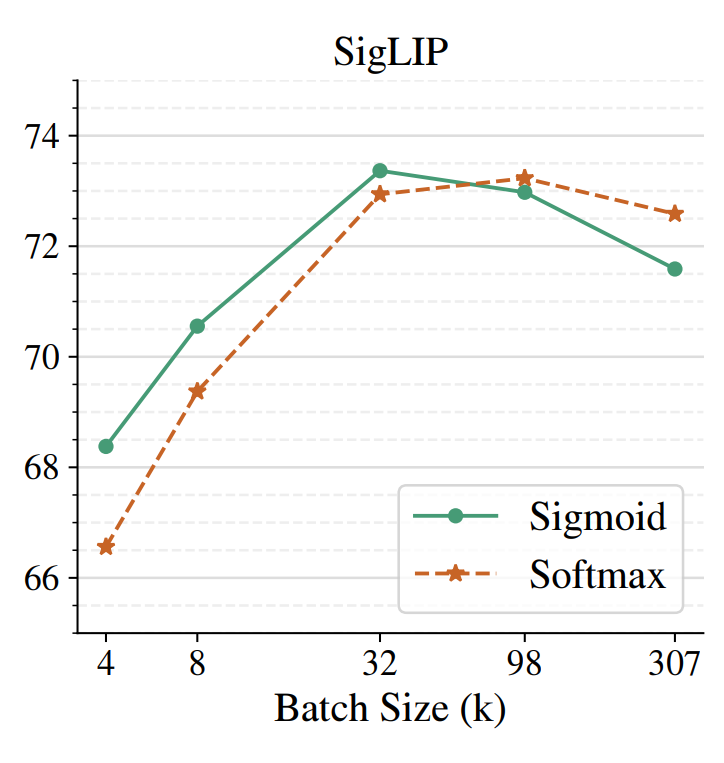
Surprisingly, we find that both SigLIP and CLIP both plateau at batch-sizes not much larger than 32k, originally used in CLIP. We also investigate the LiT (https://arxiv.org/abs/2111.079... setting, where we can reach batch-size of 1 Million. However, we see almost no benefit beyond 32k.

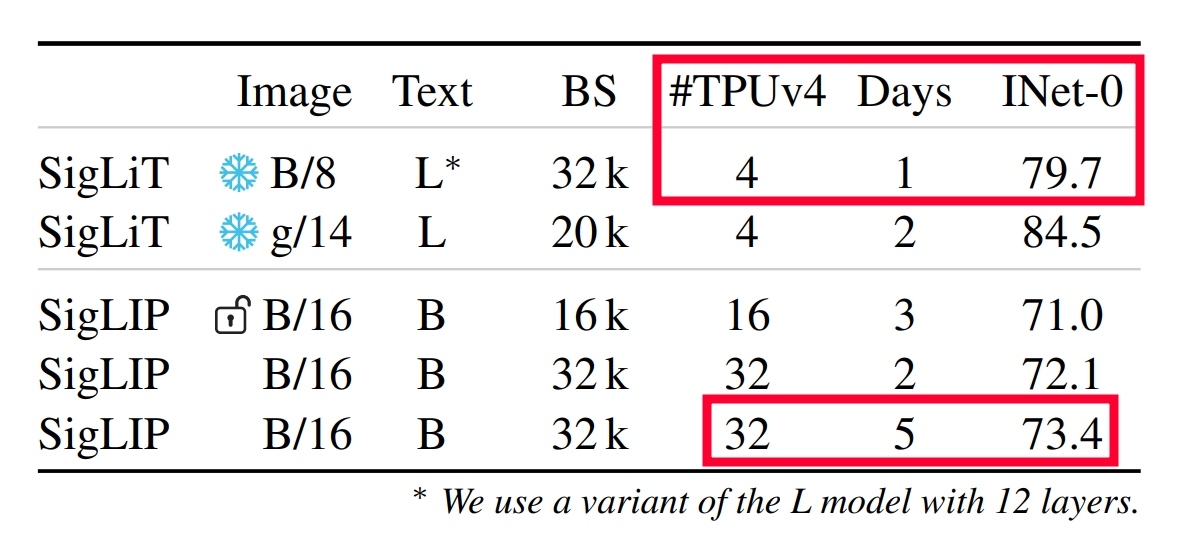
Next, we push efficiency to the extreme: - With SigLiT we get to 80% ImageNet 0shot in just 1 day on 4 devices(!!) - With SigLIP we get to 73% in 5 days on 32 devices. This is MUCH better than OpenAI (256 for 12 days?) and OpenCLIP (800? for ? days)
Here is a comparison to other notable CLIP models, just to convincingly show that this recipe is the best one publicly available right now. We've actually been using it for quite some time internally before deciding to write up a paper about it, so we're confident here.

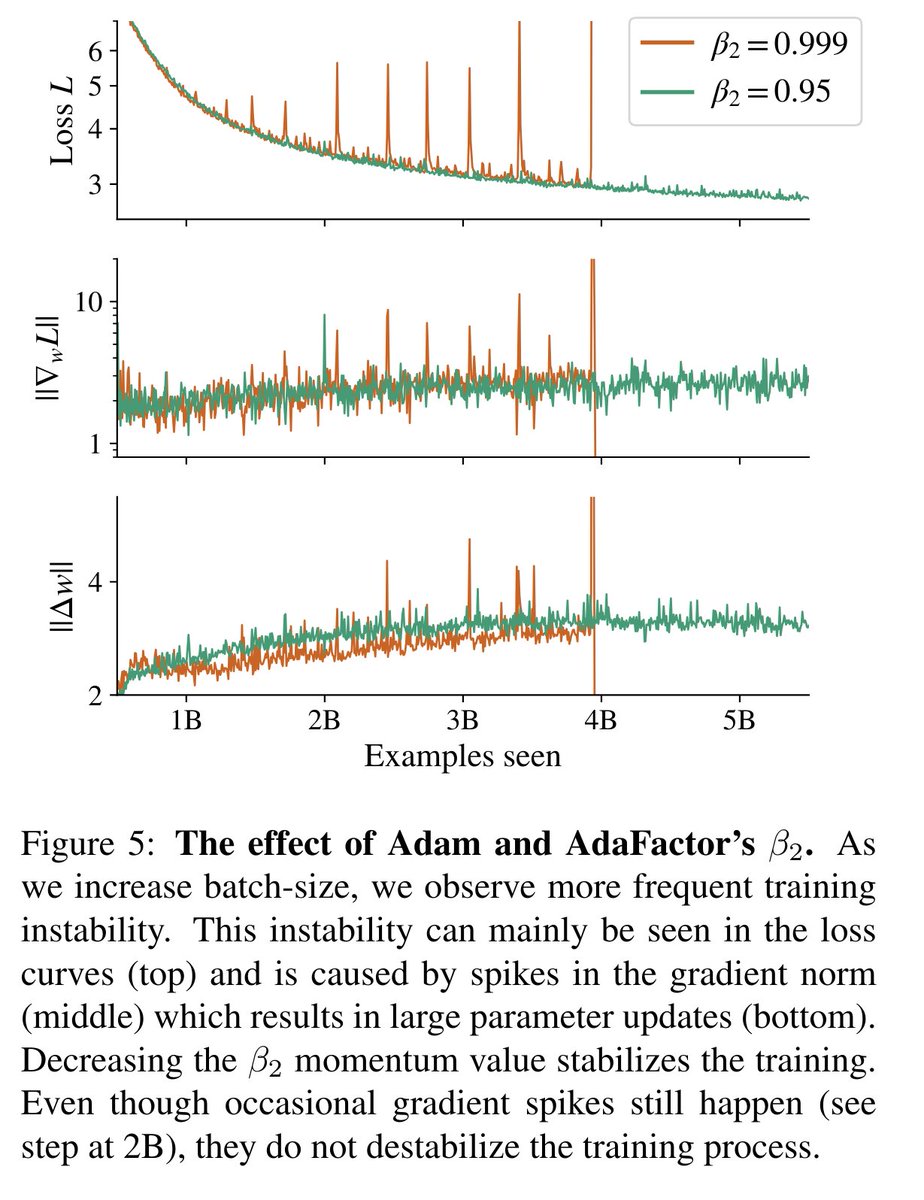
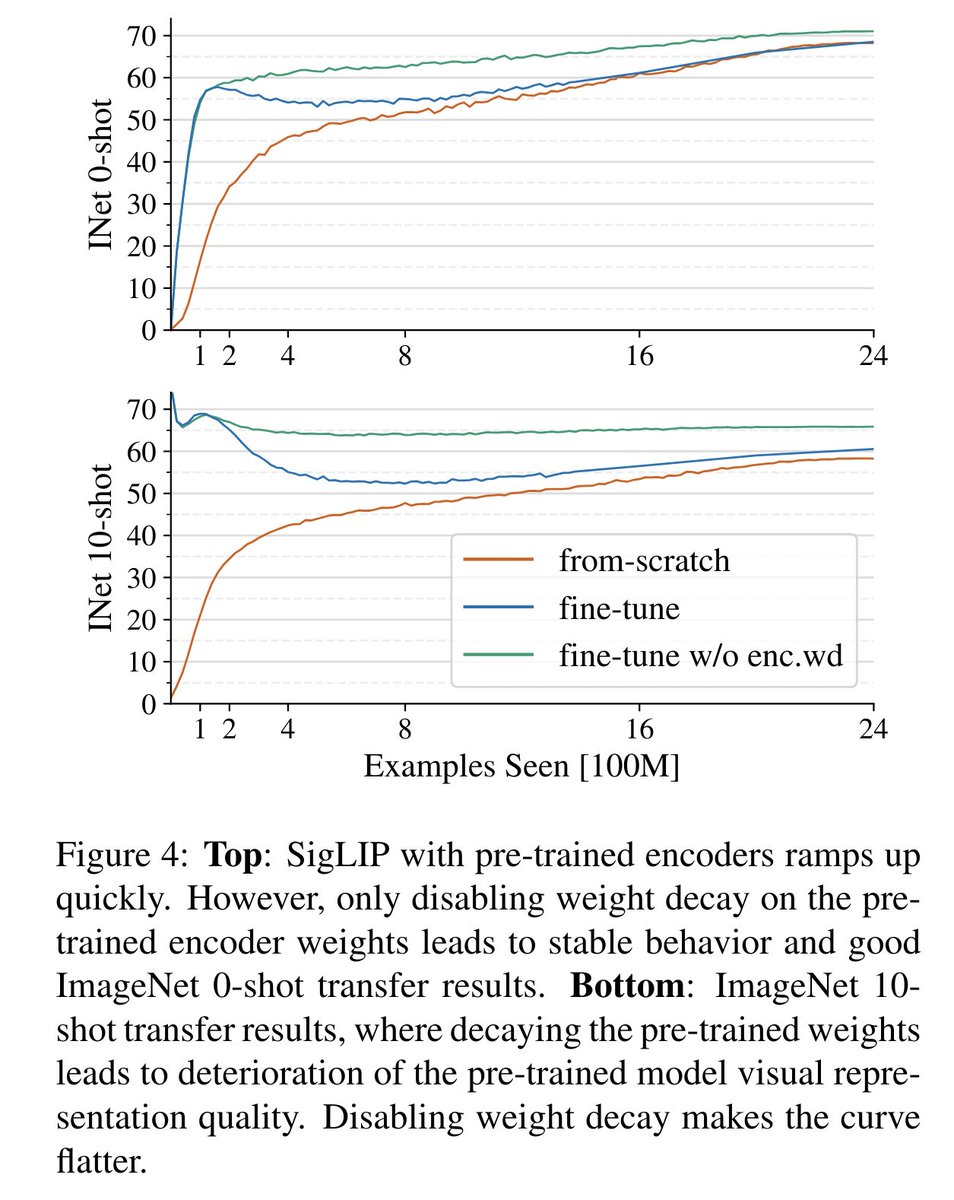
Two small bonus protips before the end: Left: If your loss spikes, try reducing Adam/AdaFactor's beta2 to 0.95 (not novel, but rarely shared) Right: When a piece of your model is pre-trained but not frozen, try not using any wd on it, but do use wd on the rand init'd pieces.
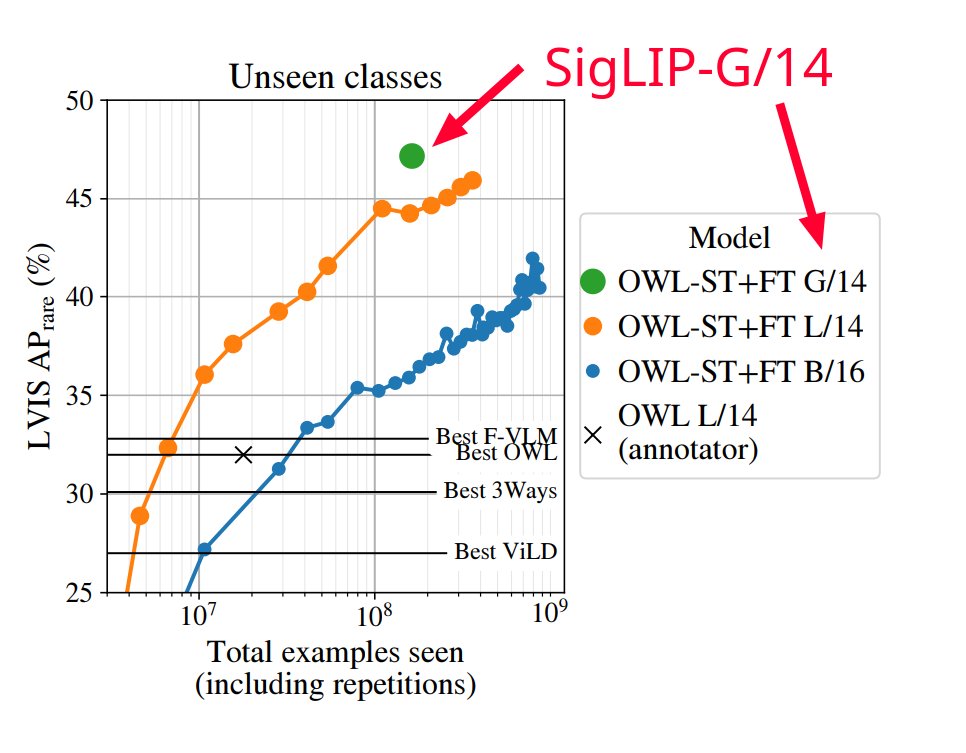
There's a few more goodies in the paper: https://arxiv.org/abs/2303.153... We also used this recipe to train the largest base model for the amazing OWL-ViT v2 open-world detector: https://arxiv.org/abs/2306.096... We're trying to open-source before ICCV🤞 Co-authors tagged in OP. End of🧶
PS: Some of my screenshots in this thread are from the updated ICCV version that's not on arxiv yet, but will appear there later.
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Are BYOL losses not competitive? I would've thought they imply "it's not the negatives".
@FeinbergVlad @XiaohuaZhai @__kolesnikov__ @_basilM Interesting connection. Not sure self-supervision and image-text behave the same, and not sure how we’d get multimodal model out of BYOL, so… maybe? Now I’m curious if SigCLR would work better too. It might, someone try!
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Curious to know if this technique could in principle also be applied to fixed vocabularies like what are used in LMs or if there's something specific about this objective that wouldn't transfer. These results are neat!
@hyperparticle @XiaohuaZhai @__kolesnikov__ @_basilM Curious too! I think it may work. We already did this successfully for ImageNet classification previously, which partially inspired SigLIP https://arxiv.org/abs/2006.071...

@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Are there any tricks like hard negative mining? I have tried training sigmoid-based contrastive models, and it never worked for me
@norpadon @XiaohuaZhai @__kolesnikov__ @_basilM No, but the learnable bias is what's easy to miss: https://x.com/giffmana/status/... And its init matters, see Tab3 in paper.
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM What is the metric for text-to-image retrieval results? Somehow can't find it in the text.
@visheratin @XiaohuaZhai @__kolesnikov__ @_basilM Top1 iirc. Oops, will fix thanks for asking !
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Wow this is amazing 🤯 Great work 👏🏻
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Slip and Slit would've been cool no
@unstable_gan @XiaohuaZhai @__kolesnikov__ @_basilM We thought of them. SLIP means underwear in French though and was already taken by another relevant paper by @sainingxie @kirillov_a_n etal, we like them and don’t want to pass them off :) SLIT makes me uneasy because low perplexity next word is throat. SigLIP is better.
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Efficient implementation aside, what's the intuition that SigLIP outperforms softmax?
@giffmana @_joaogui1 @XiaohuaZhai @__kolesnikov__ @_basilM Love the simplicity and results! Is there any theory result similar to the InfoNCEs lower bound on MI? They have MI >= log(batch size) - InfoNCE
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Thanks for the cool paper! OOC: why normalize by 1/B and not 1/B^2?
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Happy to add that our method CLAMP (Contrastive Language Assay Molecule Pre-training, ICML2023) uses the same loss: https://arxiv.org/abs/2303.033...
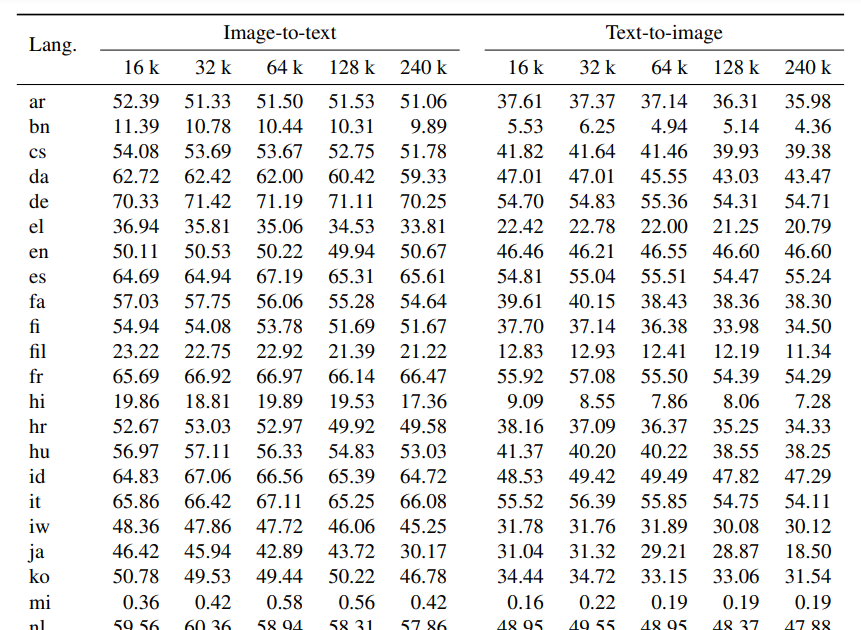
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM Another question about image retrieval - there is no Hebrew language code (he) in the table. What code did you use for it?
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM I love this, but the name leads us to a future of sigsigLips and sigsigsiglips 😝
@giffmana @XiaohuaZhai @__kolesnikov__ @_basilM CLIP-Lite is another great paper where you just need 1 negative example