
Eh bien voilà : je vous invite à discuter. J'ai rendu mes arguments aussi clairs et sourcés que possible dans cette vidéo. Si j'ai dit "n'importe quoi" au sujet de votre livre, vous n'aurez aucun mal à le montrer. https://youtu.be/dOF9vc5tLJ4
Et si vous ne savez pas par où commencer pour répondre je vous suggère deux points parmi d'autres. D'abord la quasi-absence de sources (de 13:22 à 20:15 dans la vidéo). La seule source sérieuse utilisée est un livre de Yann Le Cun de 2019 dont vous citez quelques extraits.
Par exemple voici le chapitre entier qui contient la première citation de Yann Le Cun (il y en a trois en tout dans le livre, il me semble). Je laisse chacun juger de la pertinence du développement qui suit la citation :

Le chapitre suivant n'expliquera rien de plus sur ce passage de Le Cun ni sur le lien avec votre numéro sur "On s'est déjà vu quelque part" ? Et ce numéro n'a probablement rien à voir avec le livre de Lecun puisque vous le faisiez déjà dans ce podcast : https://youtu.be/IIqKrc7t1TI?t...
Au demeurant, qu'il y ait beaucoup de recyclage d'anciennes chroniques, ce serait pas si grave si (1) c'était assumé et précisé, et (2) si c'était en lien avec le sujet de votre livre. Mais voilà ce que vous faites à la toute première page de votre livre :
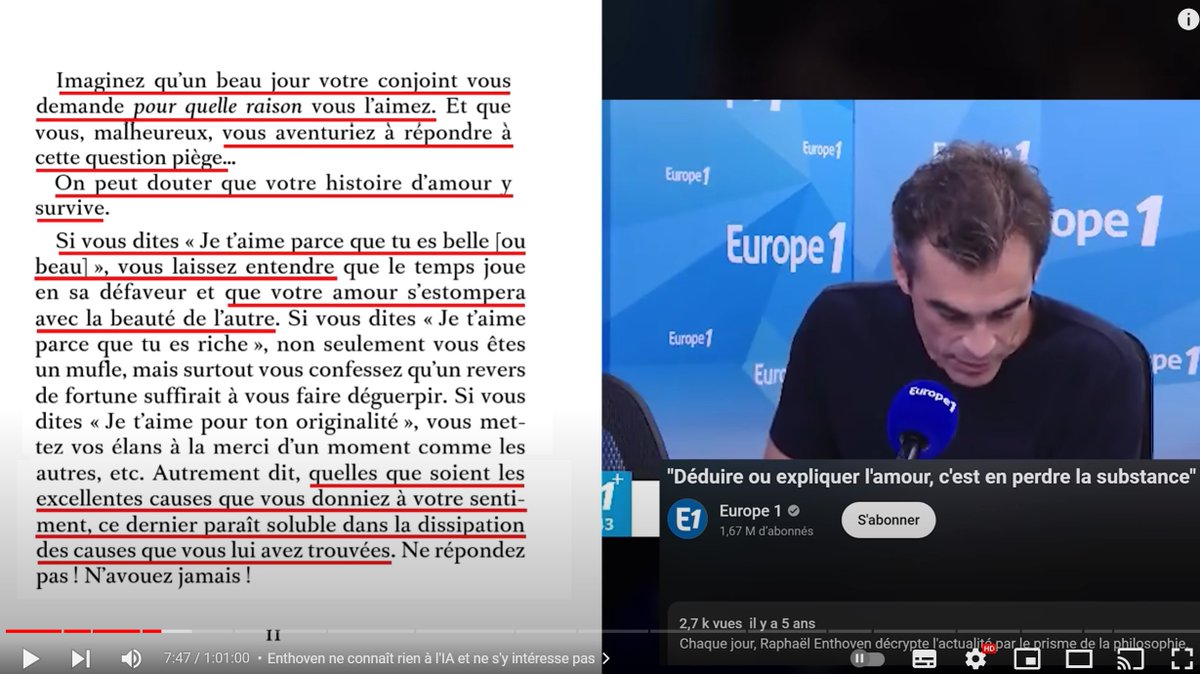
En rouge, les passage directement recyclés depuis cette chronique d'il y a cinq ans. Nulle part, ce n'est indiqué. Quant au lien avec le sujet, c'est très flou... Voici le premier chapitre complet pour s'en faire une idée. (Et ce procédé est à l'image d'une grande part du livre.)

Deuxième point, certainement le plus important. Vous avez répété à l'envi qu'une machine ne sera jamais capable de "problématiser", en donnant pour exemple votre performance contre ChatGPT-4 en juin 2023. "Même dans 1000 ans." https://x.com/Enthoven_R/statu...
De deux choses l'une. Soit vous estimez bien que cette capacité à "problématiser" est testable au moyen d'épreuves comme celle que vous aviez passé en juin 2023 contre ChatGPT. Dans ce cas, vous argumentiez de bonne foi en faisant valoir votre supériorité dans cet exercice.
Mais le problème, c'est que l'échec de ChatGPT-4 tenait surtout à l'incompétence des organisateurs de l'expérience. En réalité les LLM actuels sont déjà capable de problématiser des sujets de dissertation aussi bien voire mieux que vous ou que n'importe quel prof de philo.
Et contrairement à vous qui faites des prophéties, je fais des expériences pour tester ce que j'affirme. C'est le sens du "test de Turing philosophique" que je présente dans la vidéo de 29:03 à 48:15. Je demandais à des participants (notamment des profs de philo) de détecter
parmi trois propositions, quelle introduction était écrite par un prof de philo, et je demandais également de noter la qualité philosophique de ces introductions. Voici le résultat général :

Les votes sont généralement très partagés, avec une toute petite majorité relative pour l'humain. Par contre, pour ce qui est de la qualité philosophique, en général c'est l'un des textes écrits par ChatGPT-4 qui recueille la meilleure moyenne.
Il y avait au demeurant pas mal d'imperfections dans le dispositif qui pouvaient faciliter la tâche pour identifier les textes générés par l'IA. Sans doute en refaisant l'expérience avec une plus grande variété de prompt, j'obtiendrai de meilleurs résultats même avec le même LLM.
Quant aux résultats qu'on pourrait obtenir avec les prochaines génération de LLM, il fait peu de doute qu'on arrivera vite à quelque chose d'indiscernable des productions humaines. La tâche de "problématiser un sujet de dissertation" n'a rien d'une exception humaine, non.
Mais vous pouvez encore dire que par "problématiser" vous entendez en fait quelque chose qui n'est pas testable par le biais de ce genre de test. Ce serait *l'expérience subjective de la problématisation* qui manque à la machine, même si elle pouvait produire des textes de
problématisation objectivement indiscernable de l'humain, parce qu'en tant que machine il lui manque forcément cette intériorité. Pourquoi pas ? Votre livre pourrait en discuter et rentrer dans le débat sur le dualisme, donner des arguments pour le soutenir...
mais votre livre ne fait absolument pas ça, vous vous contentez de supposer péremptoirement toute sorte de chose sur le fonctionnement du cerveau alors que vous n'avez aucune compétence là-dedans et vous ne donnez aucune source pour appuyer vos propos...


Et vous ne pouvez pas dire que les neurosciences ne font pas de progrès ! Au demeurant, à défaut de parler de neuroscience, vous pourriez au moins présenter la littérature philosophique sur le dualisme et les débats qui l'entourent, il y aurait beaucoup de choses à discuter.
Mais non, vous ne semblez pas connaître grand chose à la littérature contemporaine sur ce sujet non plus - sans doute parce que la philosophie ne faisant pas de progrès, ce n'est pas la peine de s'y intéresser, c'est commode.
Mais bref, mon point n'est pas là. Je veux surtout souligner que partir dans cette direction, ça revient nier que "problématiser" puisse être testable empiriquement par des tests comme celui que vous avez faites en juin 2023 (ou que j'ai mieux réalisés dans mes expériences).
Mais alors pourquoi revenir sans cesse dessus ? Pourquoi pérorer sur cette victoire comme si c'était une preuve empirique de la supériorité indépassable de l'humain dans l'art de problématiser ? Pourquoi consacrer une si grande part du livre à ce test ?
Autrement dit, quand vous dites "Une machine ne pourra jamais problématiser" en faisant valoir votre victoire sur ChatGPT-4, soit vous argumentez de bonne foi sur le plan empirique et vous vous êtes trompé (mais vous auriez pu vous en rendrez compte avant d'écrire votre livre) ;
soit vous soutenez une position de principe selon laquelle les machines n'ont pas d'expérience subjective, or *vraiment problématiser* c'est faire une certaine expérience subjective, et donc, peu importe tous les tests empiriques, les machines ne pourront jamais problématiser,
mais dans ce cas, faire valoir votre victoire sur ChatGPT-4 c'est argumenter de mauvaise foi, puisque ça ne prouve absolument rien, c'est faire comme si c'était une affirmation empirique alors que ça n'en est pas une. C'est une affirmation vide, en tout cas sans valeur empirique.
En résumé, soit c'est faux, soit c'est vide.

@MonsieurPhi Ok. Mais à 4 conditions : 1) notre débat est filmé et en direct. 2) pas de pause pub. Je refuse de participer à une opération de sponsoring. 3) c’est un vrai débat. Pas un interrogatoire. J’aurai mes questions, vous aurez les vôtres. 4) lisez (ou relisez) le texte de Bergson
@Enthoven_R Le dispositif "débat filmé en direct" a toutes les chances de nuire à la qualité de l'échange : quand on veut présenter des arguments précis, réfléchis, sourcés, c'est très peu adapté et vous le savez. Dois-je en déduire que vous n'avez pas de tels arguments à donner en réponse ?
@MonsieurPhi Rafa risque de passer sous un tunnel.
@MonsieurPhi Spoiler alert: tu perds ton temps.
@MonsieurPhi Ce qui est chiant c'est qu'il pourrait pas te couper la parole toute les 2 phrases 😕
@MonsieurPhi poke @Enthoven_R