
o3, o4-miniから導入されたFlex Processingが便利かもなのでメモ📝 【Flex processingとは?】 ・o3, o4-miniからOpenAI APIに導入された新しいオプション ・多少の遅延やGPUリソースエラーの発生を許容するとAPIコストが半額に ・リクエストにパラメータを1個足すだけで利用可能 詳細はスレに↓

【安くなる理由 / 注意点】 ・Flex Processingは「即座に処理しなくても良いリクエスト」を低優先キューへ回し、OpenAI側のGPUが低負荷の際に処理するための仕組み。 ・混雑時は待たされレスポンスが遅延したり、最悪の場合はGPUリソースエラーで弾かれる。 ・その代わり支払うAPIコストは半額で済む
【どうやって利用するの?】 ・APIコールの際に"service_tier":"flex"を追加するだけ ・デフォルトのタイムアウトは10分。それ以上に遅延することもあるから注意 ・実験を並列で回して1個1個の処理時間気にしない時とか良さそう? ・OpenAI SDKを利用しているとtimeoutの際は自動的に2回再実行される
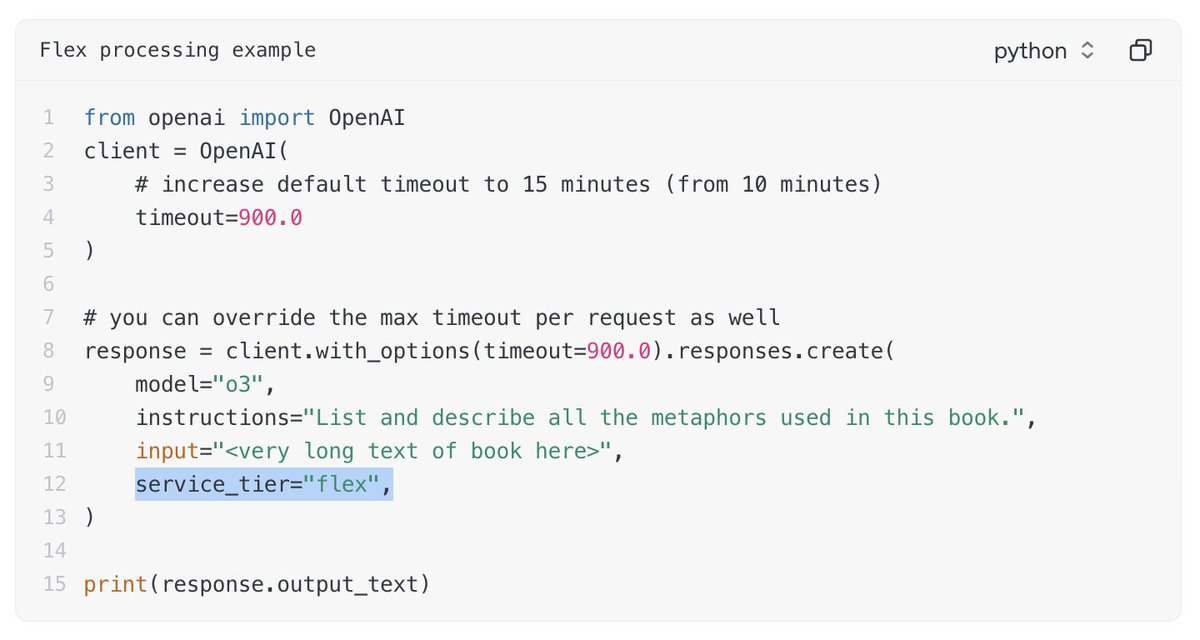
【失敗したAPIコールは課金されるの?】 ・GPUリソース不足エラーや処理待ちのまま1トークンも生成されなかった場合は課金されない ・生成中にタイムアウトを迎えた場合、生成された分は従量課金される (なのでタイムアウト長めにするといい?)
【Batch APIとの違いは?】 ・今までもBatch APIという仕組みがあり、処理の遅延を許容するとAPIコストが半額になった ・Batch APIは専用エンドポイントにJSONLを投げる必要があった ・他方、Flexは通常エンドポイントへのリクエストに1行足すだけで利用可能
・大量のバッチ処理はBatchを利用し、遅延を許容できる適時処理はFlexを利用するのが良さそう まだ本格的に試したことないので429エラー多すぎて使えないかもですが笑、Batchみたいに特別なエンドポイントに投げなくてもいいのは楽ですね。 詳細は↓のDocをご覧ください😇 https://platform.openai.com/do...