
What if AI models could figure out answers to your questions BEFORE you even ask them? 🤔 An incredible new research paper introduces "Sleep-Time Compute," allowing models to think while they aren't being used. Here's what you need to know 🧵👇

Currently, most modern LLMs rely on "Test-Time Compute." (reasoning models like GPT-o3) This means the model processes ALL the context & the query right when you ask for a response. Problem: This can lead to high latency (waiting minutes) and high costs (tens of dollars per query) for difficult problems.

A key drawback: standard test-time compute often assumes problems are 'stateless'. The model needs the entire context & query together every single time for processing. For 'stateful' applications (like document Q&A, coding assistants, conversational agents) where the context is persistent, this forces models to constantly recompute redundant information.
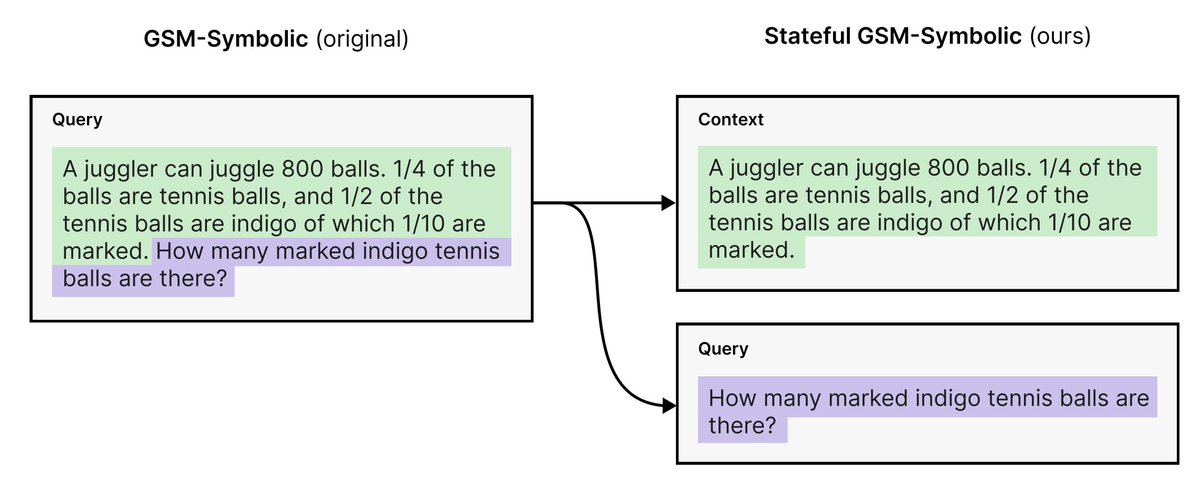
The solution? "Sleep-Time Compute." This lets the LLM "think" or pre-process information about the context OFFLINE, when the user ISN'T actively querying. It's like your brain processing info overnight!
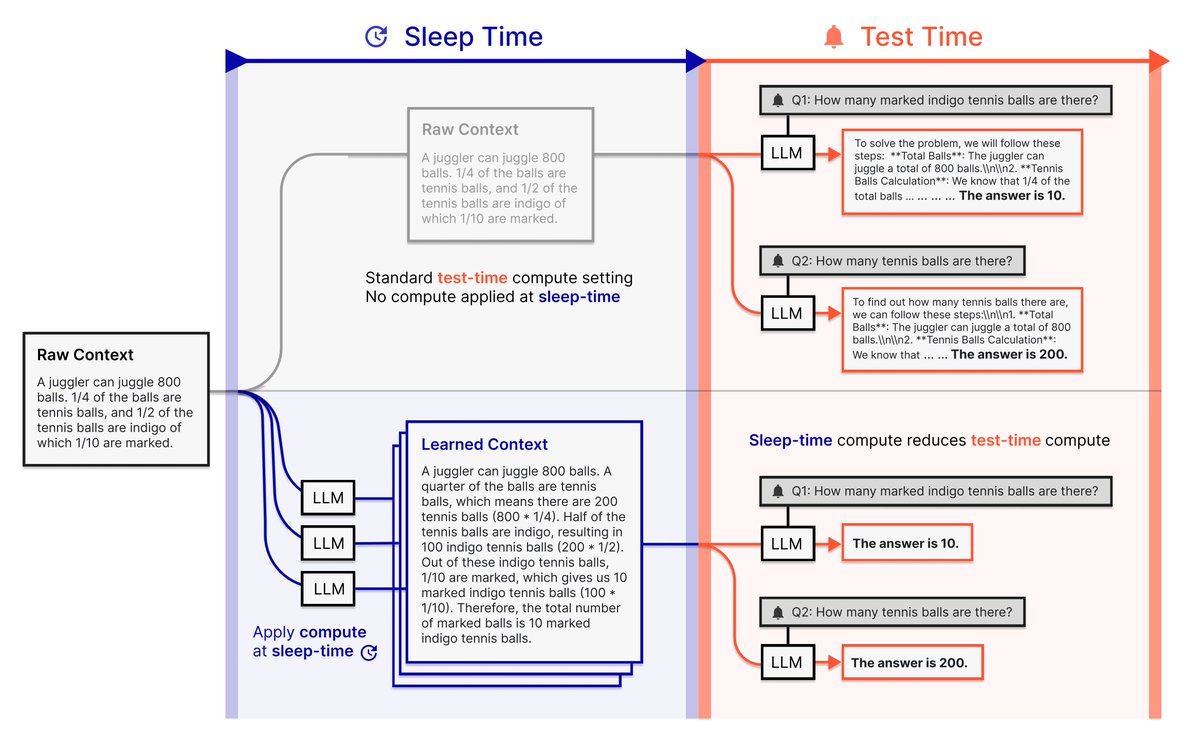
Key Benefit: SIGNIFICANT Cost Reduction! By moving redundant computation to idle "sleep" time, you can achieve similar accuracy to standard test-time compute with potentially 5x LESS expensive test-time tokens! More efficient GPU usage = lower bills.
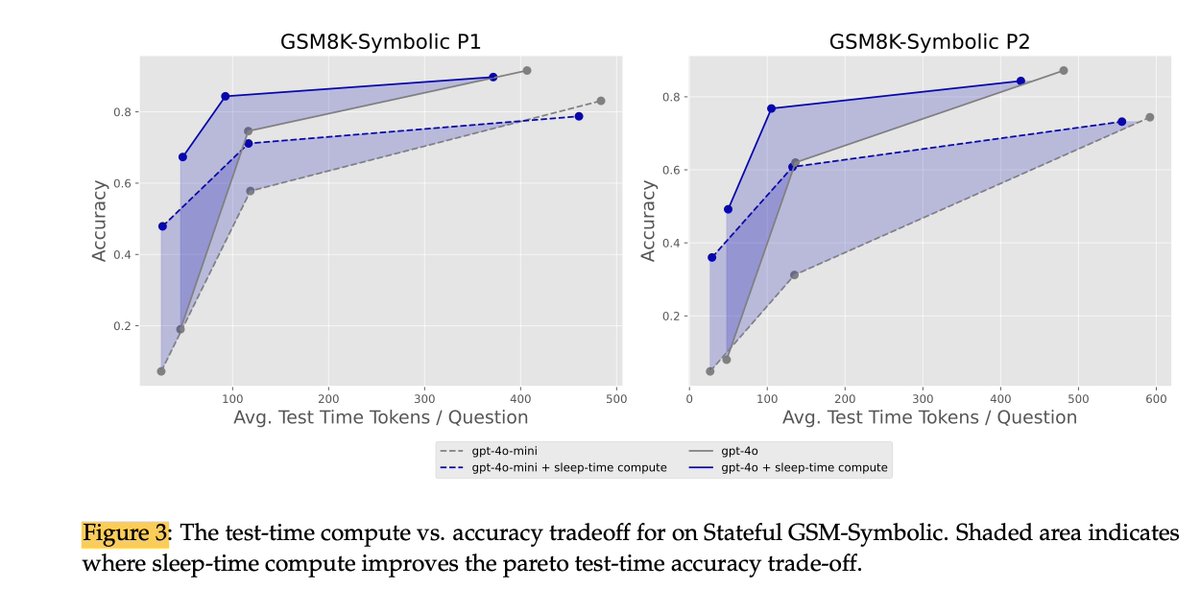
They tested this on various models (GPT-4o, Claude, DeepSeek) & benchmarks. Results show Sleep-Time Compute produces a Pareto improvement in the accuracy vs. test-time compute tradeoff. Meaning better accuracy OR lower cost for the same result.
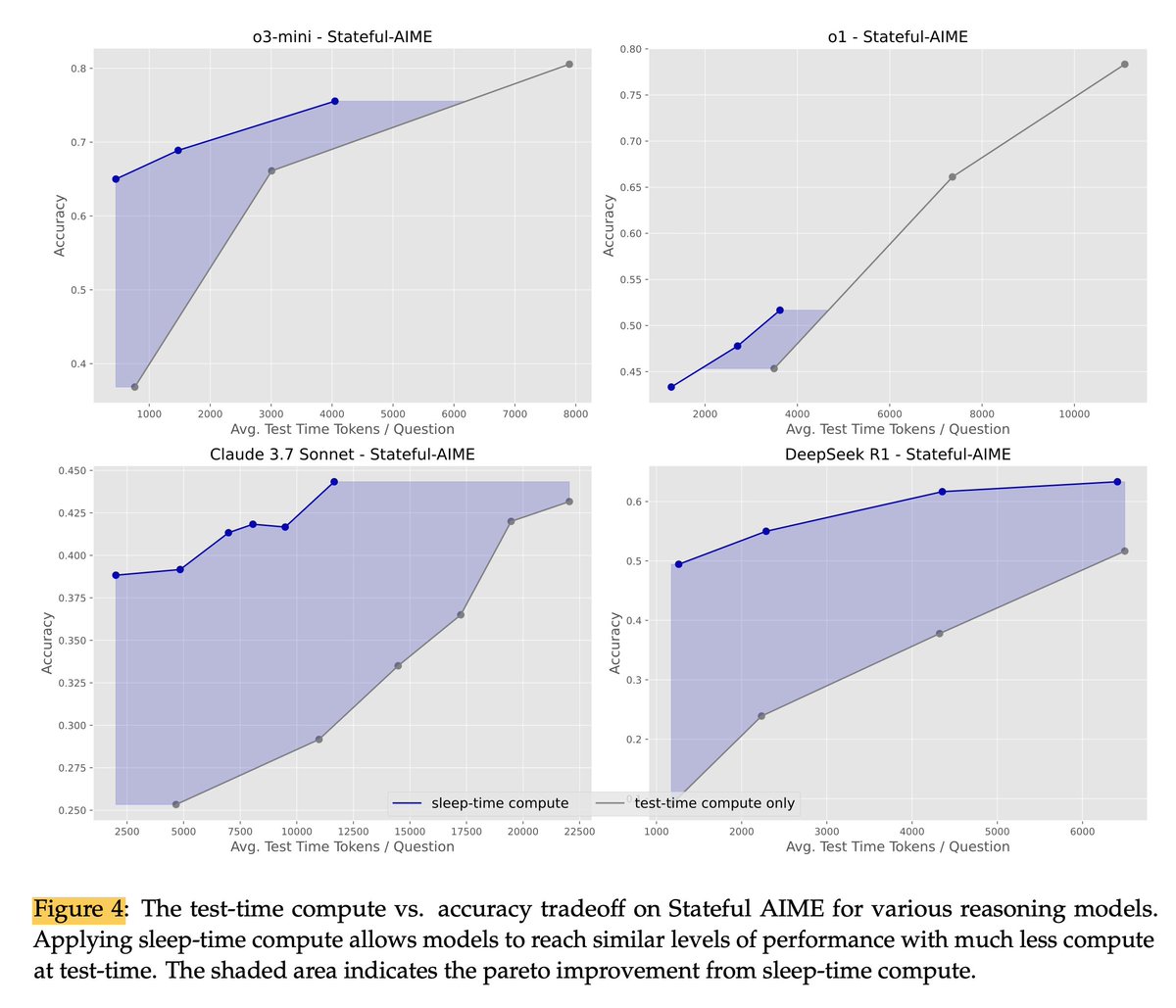
Scaling up the amount of sleep-time compute further improved accuracy by up to 13-18% on different reasoning tasks. This suggests offloading thinking to idle time allows models to perform better when it counts (at test time).

Sleep-Time Compute also consistently outperformed "parallel sampling" (another technique for low-latency inference) at the same test-time budget. This highlights its effectiveness as a way to scale inference time efficiency.

It's most effective when the questions you anticipate asking are somewhat "predictable" from the context. Pre-processing is useless if you asked questions that were unrelated to the context.

Cost amortization The cost-saving power of Sleep-Time Compute really shines in applications where users ask MULTIPLE questions about the SAME piece of context. The offline "thinking" about that context can be shared, reducing the average cost per query by up to 2.5x!

Here's the paper: https://arxiv.org/abs/2504.131... Shoutout to @letta_ai (founded by memGPT creators!) for the paper! 🙏 And my full breakdown video: https://www.youtube.com/watch?...