
Text-to-LoRA Fine-tuning effective models is hard and damn expensive! What if an AI model could help you adapt LLMs on the fly? Meet Text-to-LoRA, a hypernetwork trained to construct LoRAs in one forward pass through natural language. Here are my notes:

Paper Overview Introduces a hypernetwork-based approach, Text-to-LoRA (T2L), for instantly generating LoRA adapters from natural language task descriptions, removing the need for conventional task-specific fine-tuning.
How it works T2L is trained to generate low-rank adaptation matrices (LoRAs) for LLMs using only task descriptions, leveraging a hypernetwork to output LoRA weights in a single forward pass. It supports two training modes: reconstruction of pre-trained LoRAs and supervised
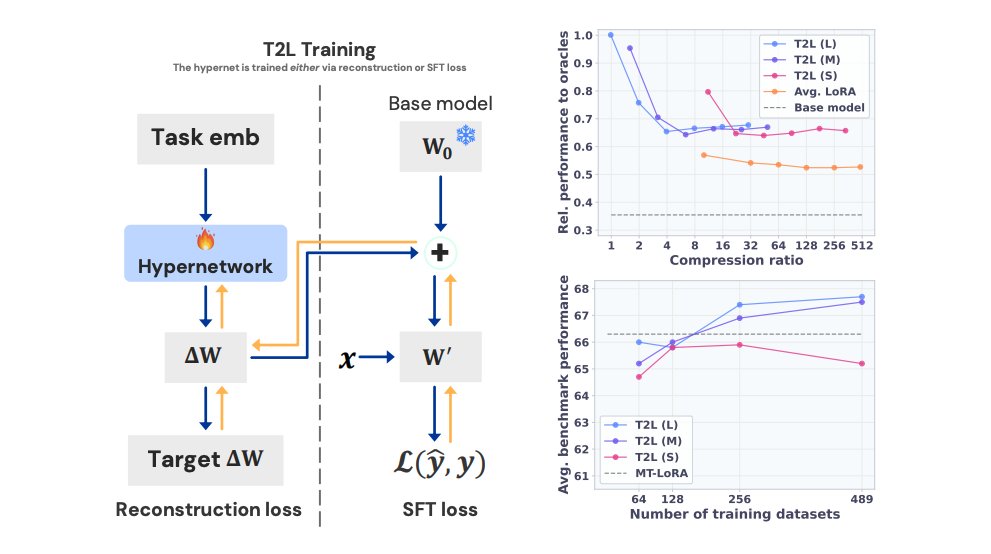
Training Schemes Reconstruction Training: T2L learns to mimic pre-trained LoRA adapters by minimizing reconstruction loss between generated and target adapters. This method compresses existing LoRAs but struggles with zero-shot generalization. Supervised Fine-Tuning (SFT):
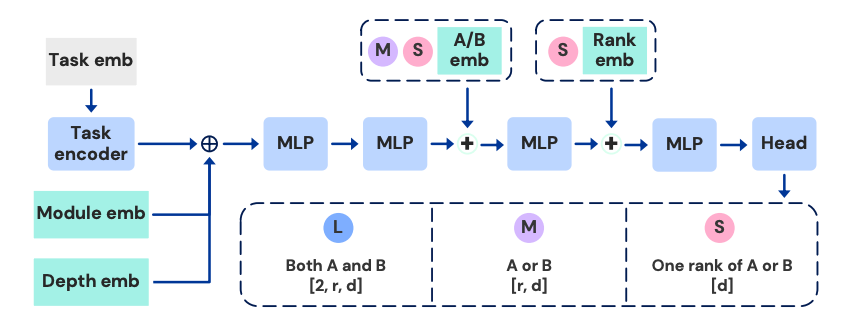
Text-Based Task Embeddings Task descriptions are embedded using models like gte-large-en-v1.5 or Mistral-7B-Instruct, allowing T2L to handle natural language instructions and generalize across diverse tasks. Task embeddings, module type, and layer indices are concatenated to
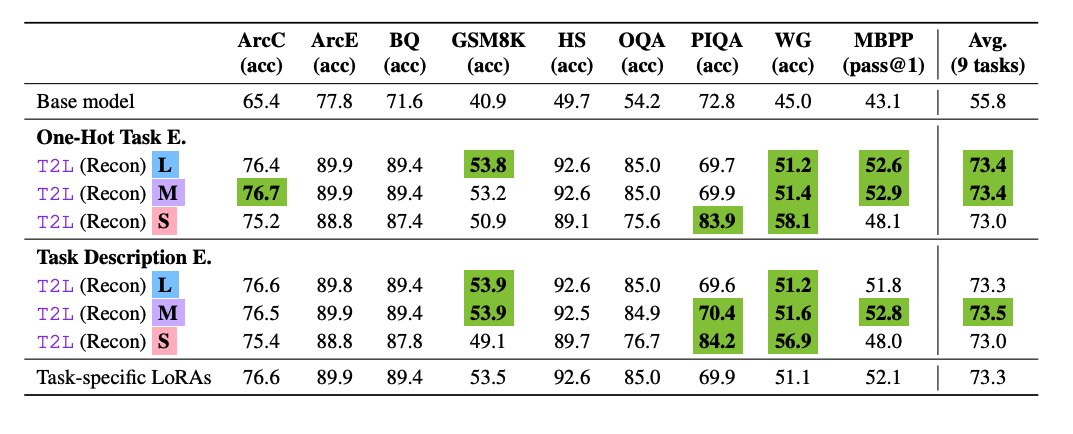
Results In benchmark experiments, SFT-trained T2L performs competitively in zero-shot adaptation, outperforming multi-task LoRA baselines and even task-specific LoRAs on some tasks (e.g., PIQA and Winogrande), showcasing generalization and compression benefits.
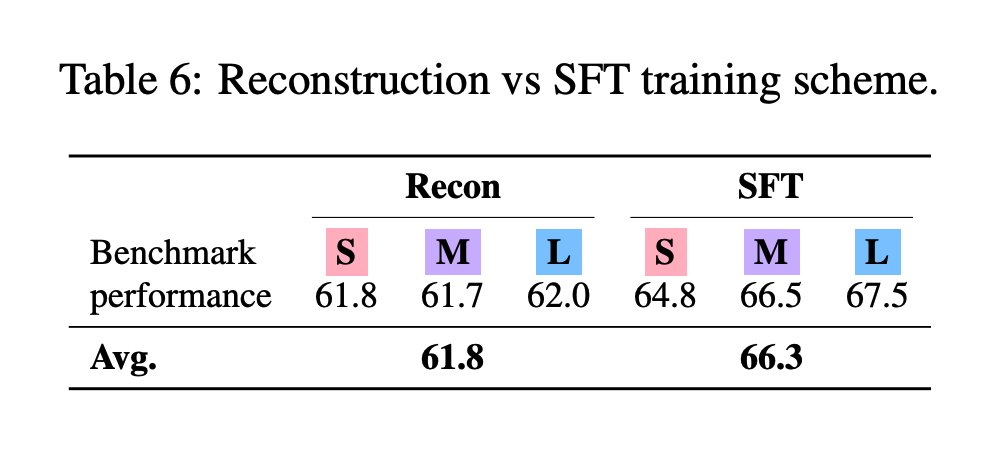
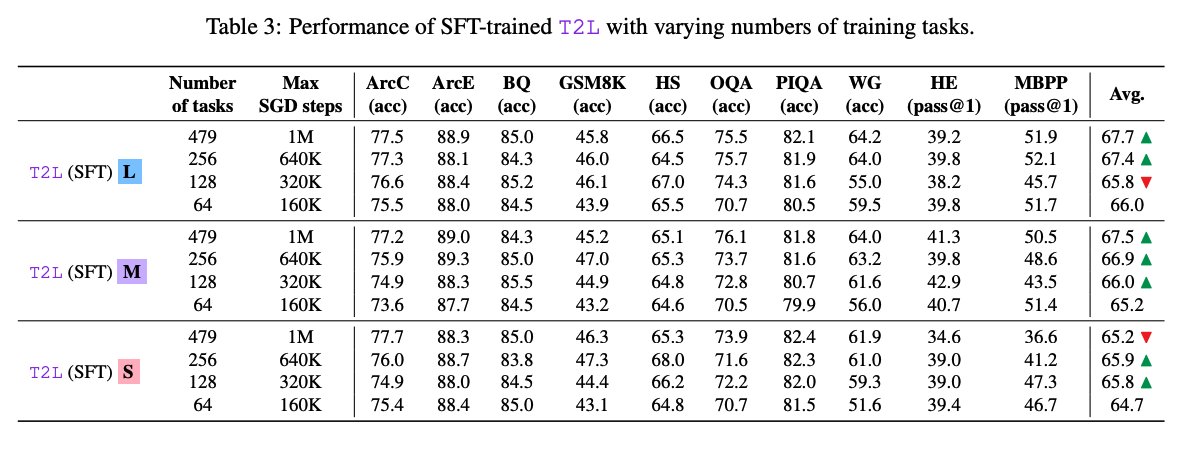
Variants The authors test three architectural variants (L, M, S) of increasing parameter efficiency. Ablations show that T2L scales well with the number of training tasks, and its performance is robust across different task description embeddings (e.g., from GTE or Mistral
Scalability and Efficiency T2L can encode hundreds of adapters and scale with additional training tasks. FLOPs analysis shows that T2L is 4–5× more compute-efficient than 3-shot ICL for generating task-specific behavior.
Visual Analyses Qualitative and visual analyses (e.g., t-SNE plots) confirm that T2L produces task-specific and semantically meaningful adapters even for unseen tasks, with steerability controlled by how the task is described. Overall, T2L is a novel approach for instant LLM
