
Attention! A new and improved attention mechanism has just been proposed by MIT, NVIDIA, Princeton, and others. Radial Attention is a sparse, static attention mechanism with O(n log n) complexity. It focuses on nearby tokens and shrinks the attention window over time. It can also work with LoRA-based fine-tuning on existing models. Results: ⚡ Up to 1.9× faster inference ✅ 4× longer videos 💰 4.4× cheaper training They also identify a phenomenon termed Spatiotemporal Energy Decay in video diffusion models: post-softmax attention scores diminish as spatial and temporal distance between tokens increase, akin to the physical decay of signal or waves over space and time in nature.
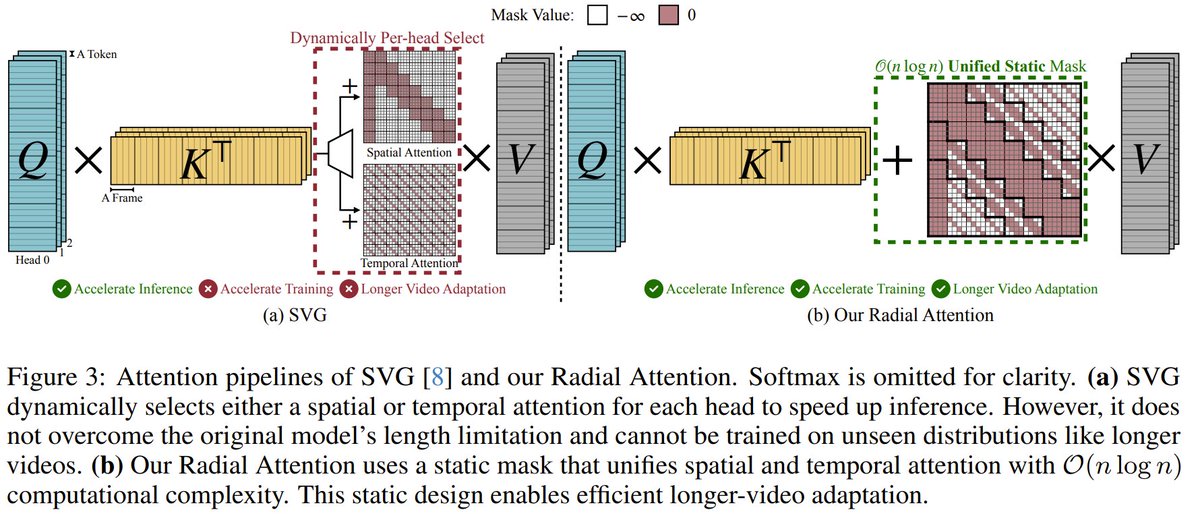
Radial Attention: O(n log n) Sparse Attention with Energy Decay for Long Video Generation Paper: https://arxiv.org/pdf/2506.198... Code: https://github.com/mit-han-lab...
