
Some benchmarks on local AI I did this afternoon 2 machines with 64GB Unified Memory: Macbook M2 Max vs. NVIDIA AGX Orin. Who wins?


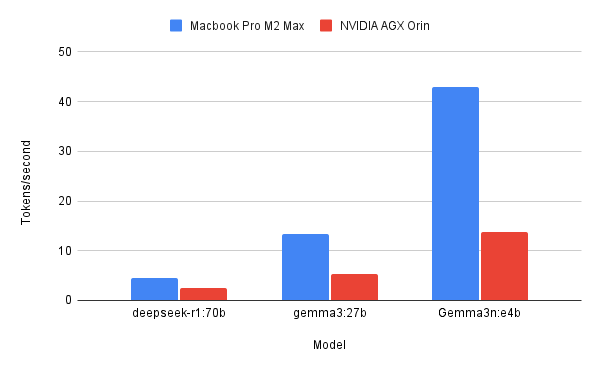
Started strong with a chonky model, deepseek-r1:70b mf is 43GB heavy, so forget about running it in a GPU. Unified memory is the way to go. M2 Max was 1.8x faster than the Orin 🙀


I thought that with a smaller model there might be less difference, so I tried the same prompt with gemma3:27b, sitting at 17GB. Boy, was I wrong... the difference was 2.5x faster for the M2! M2 starts feeling very usable, while AGX is pretty slow still
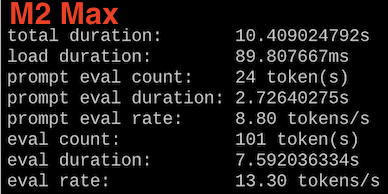

Does the difference keep growing? I tested with gemma3n:e4b, multimodal weighing 3.3GB M2 Flies, while the AGX Orin is just now reaching 13 tokens/sec, which the M2 did with a model much larger than this. The difference is now 3.11x faster 😅
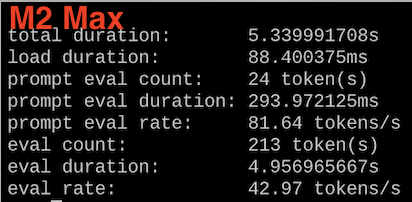

A little chart with the results
I can't wait to get my hands on a Ryzen AI Max+ 395 or a NVIDIA DGX Spark and see how they compare!