
Last week, @mims asked us if NVIDIA’s claims for 30x inference performance with Blackwell were exaggerated. We said yes, 30x improvement is gen-on-gen, doesn’t consider perf/$, and only applies in specific scenarios (large MOE’s). So, Chris put me on the front page of wsj dot


To be clear, NVIDIA claims that the GB200 NVL72 is 30x faster than HGX H100. This is not a perf/$ or perf/W claim. We think that the 30x number is misleading people.


Now lets look at Groq. Things are going well: Groq claims that their market share grew last year! 36% of respondents to an industry survey said that they are considering using Groq! But OpenAI is at 80% and Google is at 68% ... https://x.com/DylanMitic/statu...
Personally I would consider using everyone with a model and an API token. But then I would actually use a model from a frontier lab: ChatGPT, Gemini, Claude, Grok, or if I needed open source, Deepseek, Kimi, Qwen… Here's some screenshots of the @lmarena_ai leaderboard:

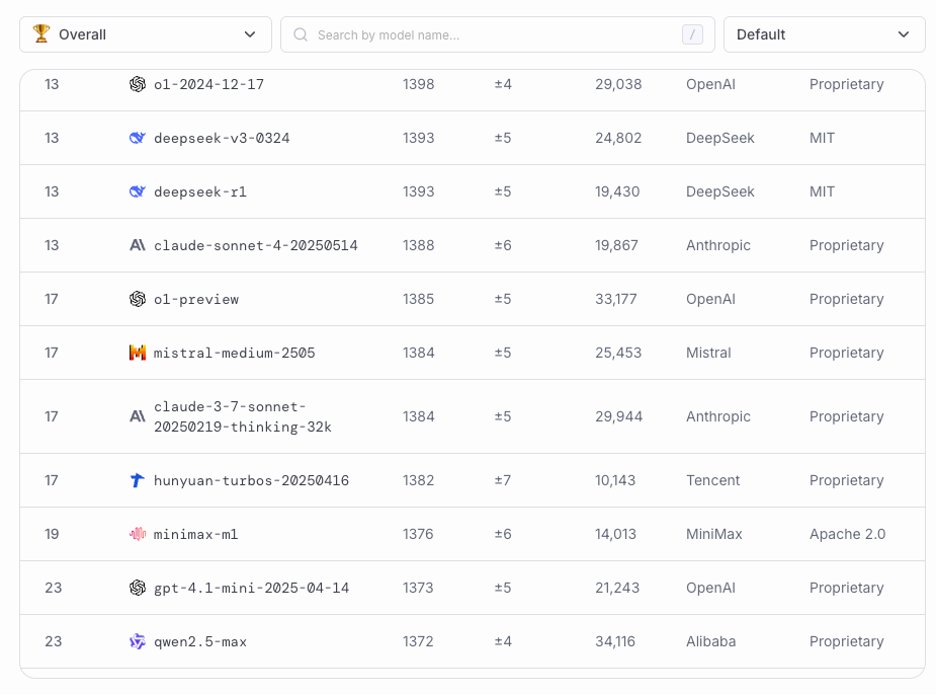
@lmarena_ai So does Groq support any of these? Clearly no to the close source models. But they do have Kimi! Glad that they picked the #1 performing OSS model and awesome that they can do it so quickly! But, missing the full versions of DeepSeek and Qwen...

@lmarena_ai So clearly Groq doesn’t have a problem with chinese models. But they offer lots of Llama4, and no Qwen? Interesting choice. https://x.com/jiqizhixin/statu...
@lmarena_ai Lets look at Kimi. I made an account on GroqCloud and used their chat interface. Result: 291 tok/sec Pretty cool to see it that fast!
@lmarena_ai I also tried Kimi on OpenRouter. They have a free endpoint up, which did 19.2 tok/sec for me. Not bad. Certainly usable for chat, faster than I can read. If I wanted this for coding assistance, I might look for a faster option. Certainly need something faster for realtime
@lmarena_ai So can Groq deliver good performance per user? Yeah, it’s great. We call this interactivity, the number of tokens/sec that an individual user sees. But that’s not the whole story. Groq raised $300M in funding in 2021, and another $640M in 2024 at $2.8B valuation.

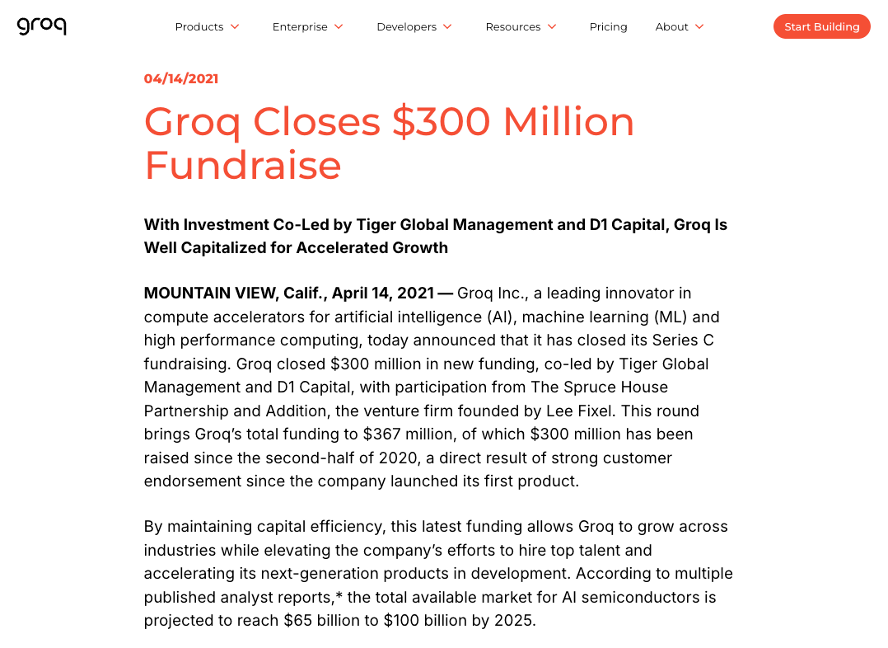
@lmarena_ai In the same 2024 press release, they claim 360,000 signups for GroqCloud and 108,000 LPUs to be deployed


@lmarena_ai So what is an LPU? Well, if you ask Groq, they don’t want to tell you anymore:

@lmarena_ai So I’ll source from our article instead “Groq Inference Tokenomics: Speed, But At What Cost?” https://semianalysis.com/2024/...
@lmarena_ai “Groq’s chip has a fully deterministic VLIW architecture, with no buffers, and it reaches ~725mm2 die size on Global Foundries 14nm process node. It has no external memory, and it keeps weights, KVCache, and activations, etc all on-chip during processing. Because each chip only


@lmarena_ai At the time, the team analyzed the Mixtral model from Mistral: a popular open source model and the first one to use MOE. The original Mixtral is an 8x7B model. This means 46.7B total and 12.9B active params. 32k context. https://mistral.ai/news/mixtra...
@lmarena_ai Remember: 230MB of SRAM per chip. So (46.7B params * 2 bytes per param in fp16) / 230MB per chip = 406 LPUs needed just to load the model weights. And you need space for kv cache too (i.e. the context window). Result: round it up to an even 576 LPUs

@lmarena_ai Now lets compare to Kimi. Kimi K2 has 1T total and 46.7B active params. 128k context. This model is just so much bigger. Kimi K2 has 21x more total params, 2.5x more active params, and a 4x larger context window than the original Mixtral model. https://moonshotai.github.io/K...
@lmarena_ai Remember: 230MB of SRAM per chip. So if the same LPU that ran Mixtral is running the full Kimi K2 (no distill), that means: (1T params * 2bytes per param in fp16) / 230MB = 8,695 LPUs just for the weights!
@lmarena_ai When I punched in a question on GroqCloud did I seriously just get a response from like 10,000 LPUs? I think so...
@lmarena_ai Clearly, there was lots of optimization work done over the last year by everyone working on inference: fp8/fp6/fp4 quantization of both weights and kv cache. Disaggregated prefill/decode. KV cache expansion to DRAM and NVMe. The list goes on. But, all of these optimizations kind
@lmarena_ai There is lots of DRAM in the Groq servers that host the LPUs! Just not sure its being used.

@lmarena_ai At the end of the day it is a question of interactivity vs total throughput. In other words, to run a profitable inference endpoint business, you probably want to run at a high batch size to drive your cost down. Of course, you need to balance this with interactivity, so that
@lmarena_ai It seems like chips with HBM on them, such as NVIDA H100, B200, AWS Trainium, Google TPU, and AMD MI300X, MI355X are able to strike this balance. It also seems obvious that models are growing in size, as users look for higher quality rather than faster outputs.
@lmarena_ai To restated this power analysis with 10k LPUs for Kimi K2 is just egregious: (3.2kW per 8-chip server) * (1250 8-chip servers) = 4000 kW = 4 MW At $35k per 8-chip server that is over $40M of hardware running Kimi K2. And a big chunk of the 108,000 LPUs announced.

@lmarena_ai Comparatively, you can run Kimi K2 on 16x H200 (i.e. 2x DGX servers)... Or, you can run with PD disaggregation and achieve 24,000 output tokens/sec, per 128x H200 deployment That’s 187.5 tok/sec per GPU Or ~$0.21 per 1M output tokens on H200 (at LMSYS costs)

@lmarena_ai And you can still balance between interactivity and throughput as you see fit. That’s 160 kW for the full cluster, or 20kW for the 2x DGX servers and single instance of K2. https://lmsys.org/blog/2025-07...
@lmarena_ai >> The question that really matters though, is if low latency small model inference is a large enough market on its own, and if it is, is it worth having specialized infrastructure when flexible GPU infrastructure can get close to the same cost and be redeployed for throughput or

@lmarena_ai So lets revisit the comments in the WSJ: “Groq claims its chips can deliver AI much faster than NVIDIA’s best chips” True: Groq can tune for interactivity and do things on a per-user basis that NVIDIA can’t

@lmarena_ai “... and for between one-third and one-sixth as much power as NVIDIA’s” Highly misleading at best. Groq’s chips are smaller, sure. But you need way more LPU’s than GPU’s to run an equivalently sized model. Power (and $) is wasted on everything else in the system that’s not a
@lmarena_ai “While the specifics of how Groq’s chips perform depends on any number of factors” Yeah, three factors: which model are you using (# of params, size of ctx), what is the average input/output profile (# of tokens), and how many concurrent requests are you handling (i.e. how many
@lmarena_ai “The company’s claim that it can deliver inference at a lower cost than is possible with NVDIA’s systems is credible” Disagree. Groq does exactly one thing NVIDIA can’t, at any price: run models at very high interactivity. This does not mean Groq delivers inference at lower
@lmarena_ai Correction: I H200 performance per GPU on Kimi K2 is wrong here It’s 24,000 output tok/sec per node (not 128x H200 cluster) Which means 3,000 output tok/sec per H200 GPU. Way more than the 187.5 I said… that should have been obvious
@JordanNanos @mims Nice thread, but a couple things aren’t adding up to me: 1. Kimi K2 isn’t fp16 like you say, it’s fp8. At the very least with your napkin math, this should 1/2 all of your estimates. 2. Unless I missed it, you don’t seem to state or claim anything about Groq’s aggregate
@JordanNanos @mims I’m gonna need a TLDR on this! 😅
@darkseidzz @mims Groq has made a Ferrari. It is really fast, and carries one or two passengers. But if the passenger is heavy you need to put 10,000 wheels on the car NVIDIA, Google, AWS, AMD and others make 18-wheelers. They can go 100km/h on the highway, but can’t go 300km/h on the track. It