
Hinton ~1983 thought Boltzmann Machines > backprop, but debugged himself out of the infatuation Boltzmann Machines failed to learn, so he printed out weights, 8 cm thick, and inspected them for weeks it's the dreaded local minimum so 1 yr later, in desperation, he tried backprop


In the 1980s it was standard to print out *all* the weights and interpret them. They would use white squares for positive weights and black squares for negative weights. The sizes represent weight size. So you could point and say "This dark wave represents concept X..."

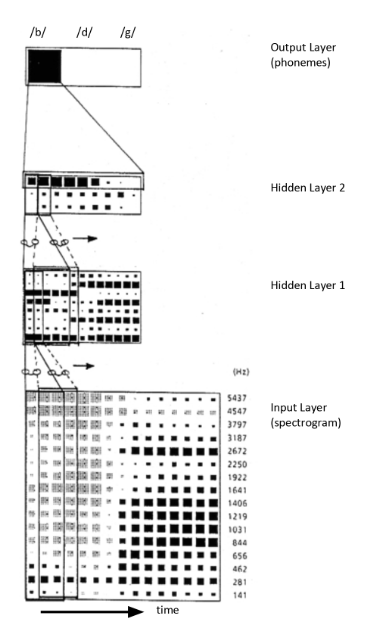
in CNN, it was standard to do something similar: print all the neural activations (not the weights) on various representative datapoints LeCun's LeNet-5 page has a lot of those.
"Take a look at this." "What?" "Look! Pixel37-48 at conv3-8 is doing that weird blinking thing again when I shift MNIST-23183." "Damn, I knew that 1.72 is too good to be true. Reset it to 1.7159!"

They would literally inspect *every single error* to figure out what went wrong on *this* datapoint, and maybe apologize for them. How honorable. ---- Le Cun, Yann, et al. "Handwritten digit recognition: Applications of neural net chips and automatic learning." Neurocomputing:



Peter Norvig recalls in an interview:
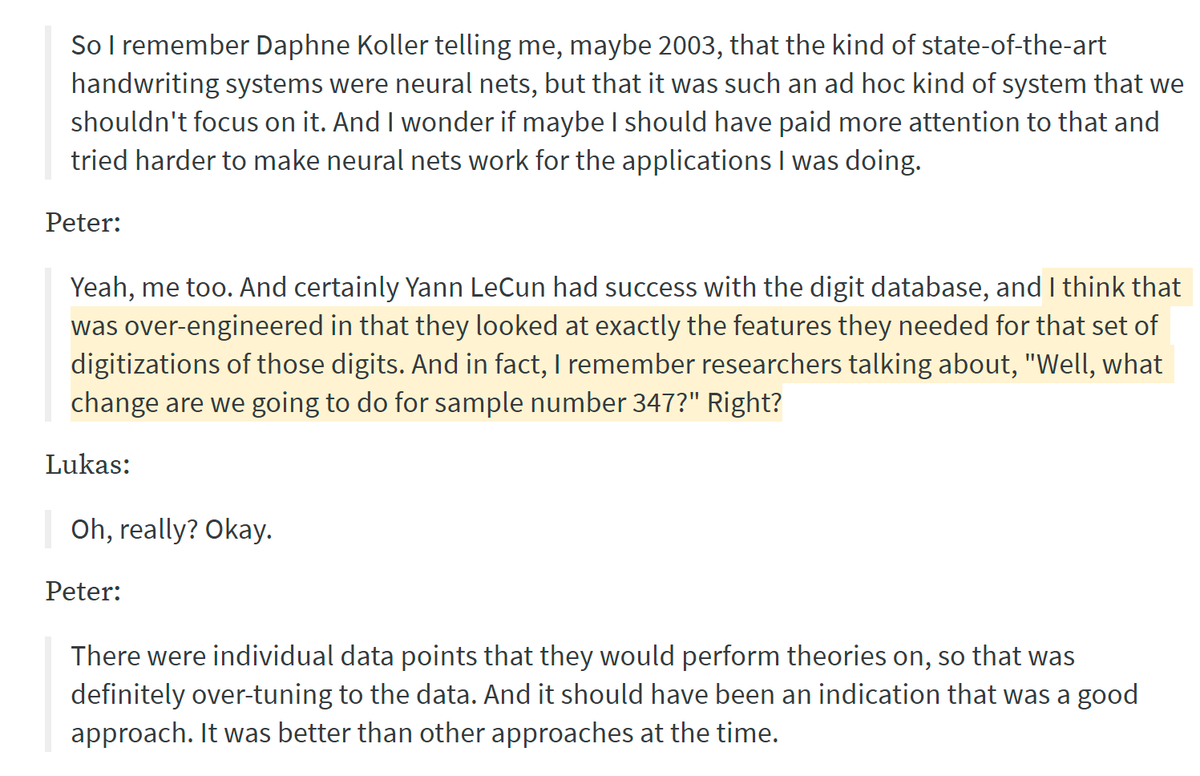
Pomerleau: Make sure your self-driving car (with 75 neurons) outputs these desirable numbers: 0.10, 0.32, 0.61, 0.89, 1.00, 0.89, 0.61, 0.32, 0.10. And make sure to interpret every single of its 29 hidden neurons!
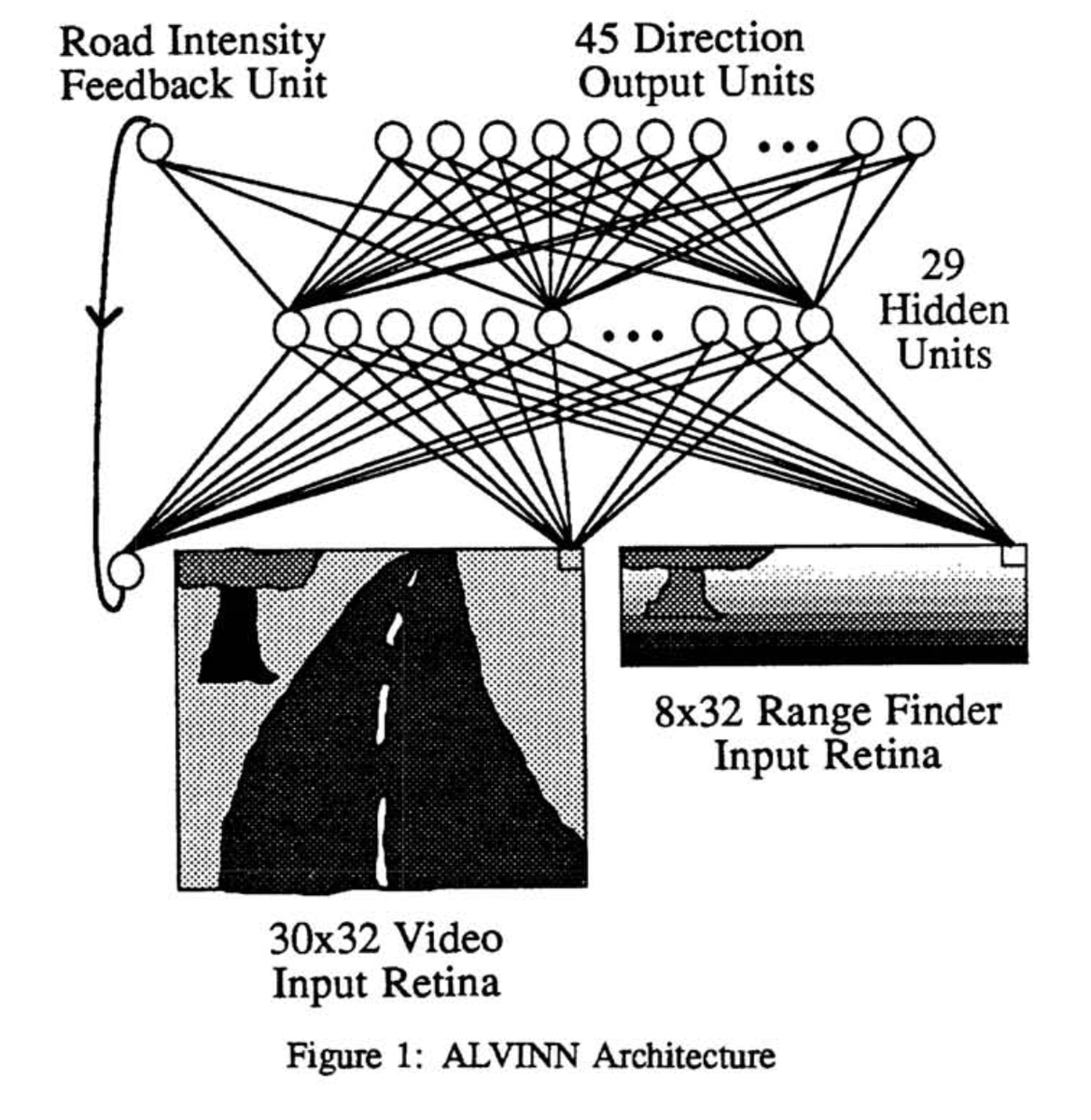

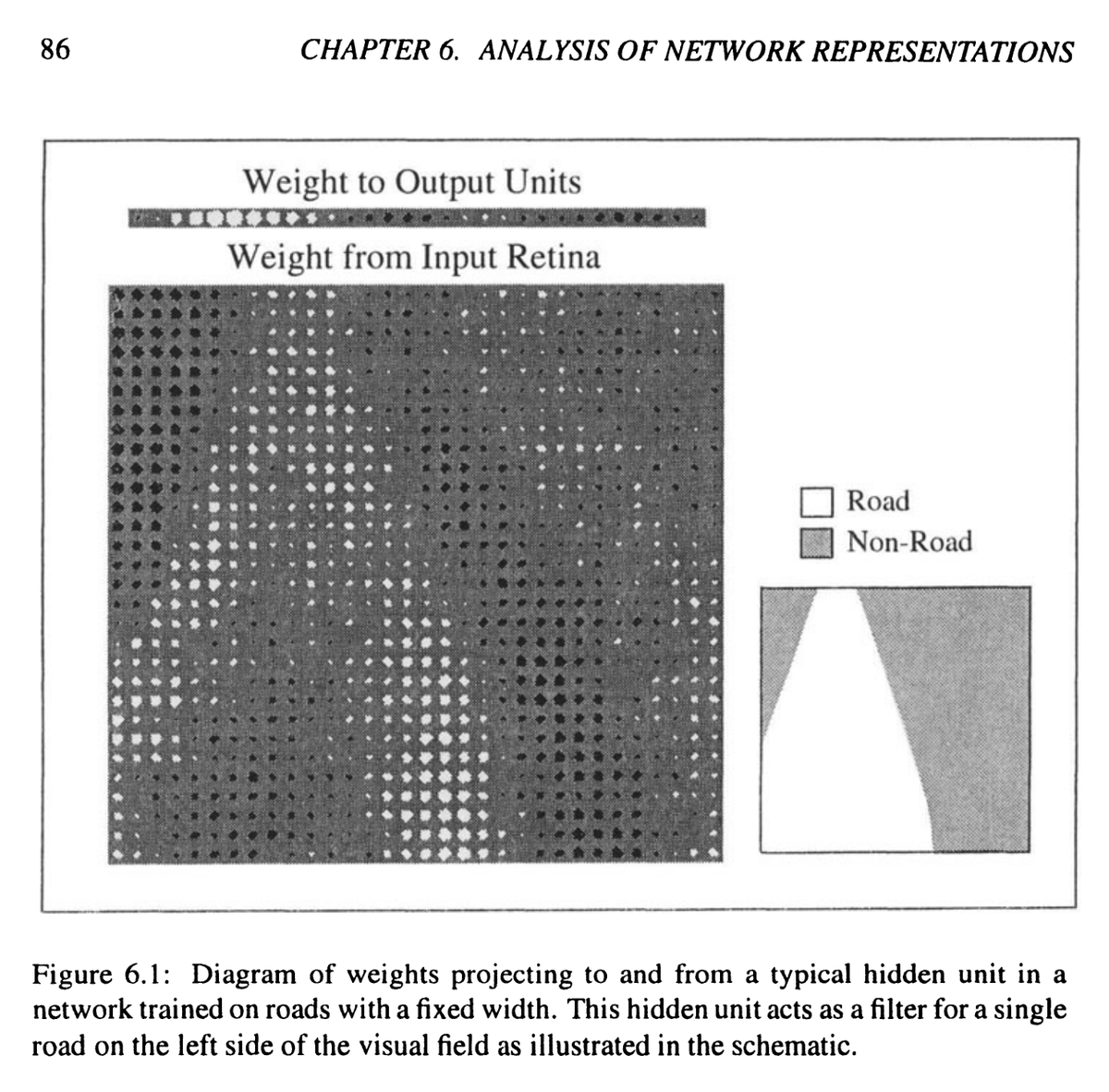
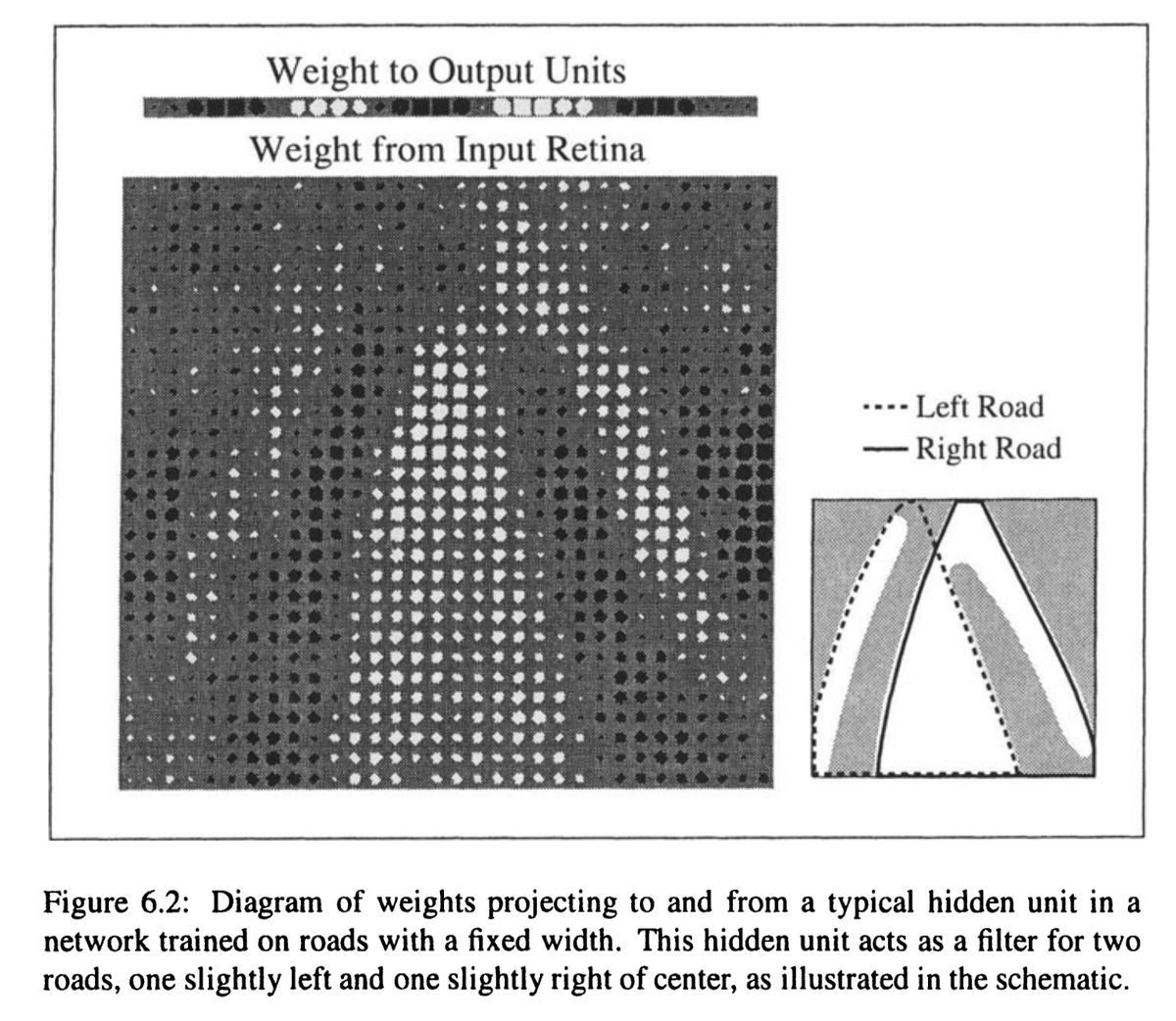
It's a really good PhD thesis, btw. It's about ALVINN (1989--1993), perhaps the first neural network self-driving car. In terms of historical impact, much more than DARPA's ALV project (which never used neural nets).
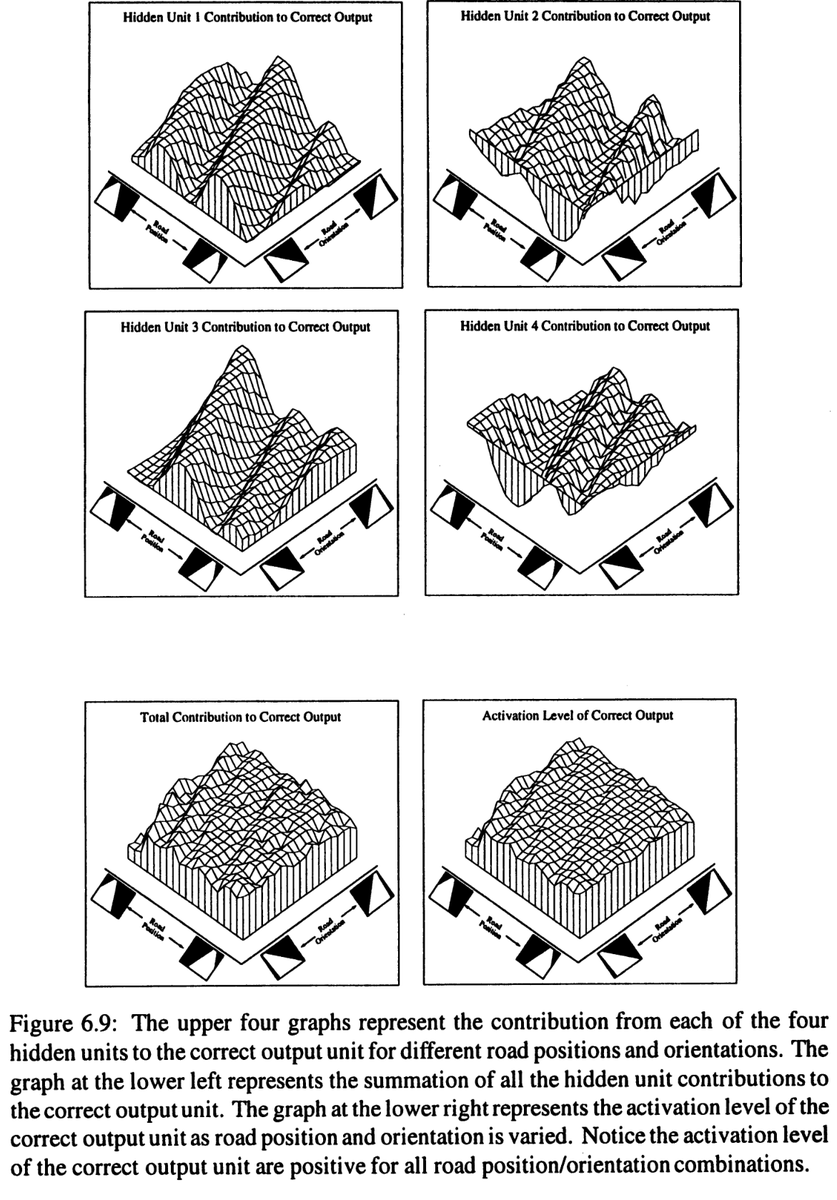
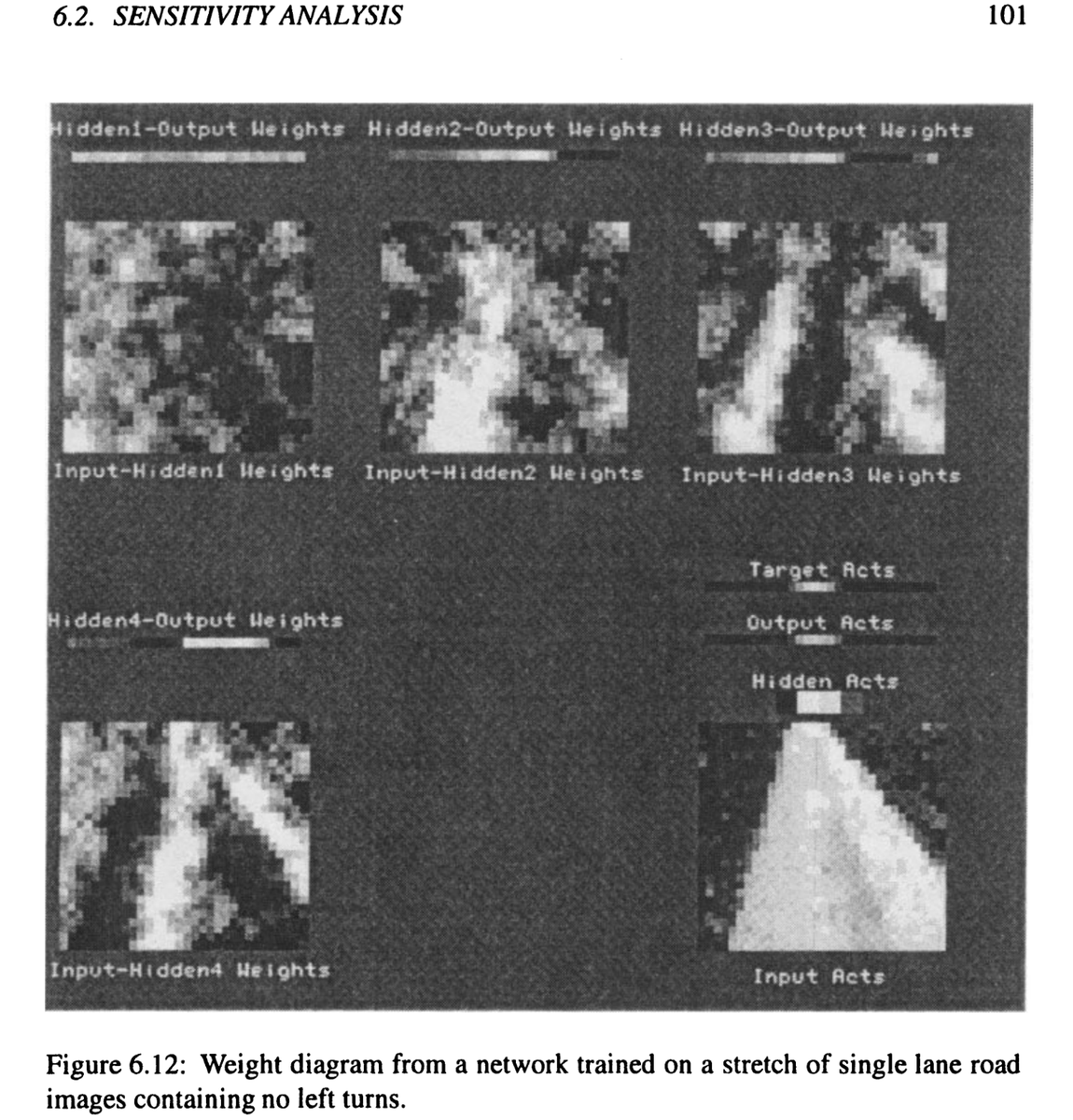


@layer07_yuxi Then he went back to Boltzmann machines 20 years later, and it *still* didn't work...
@pfau he had already gone back to Boltzmann machines ~1995, and only stumbled into ReLU by an egregious hack "just use ReLU" "no" "Okay what if [1 whole page of argument about Boltzmann machines]" "sure"

@layer07_yuxi From which book it is taken? Can you tell me please? This looks interesting!
@NavedTheNerd Talking Nets: An Oral History of Neural Networks
@layer07_yuxi It just shows that in the early days they really didn’t understand that backpropagation is just using the chain rule to compute the gradient so that we can do gradient descent (or a similar optimization algorithm). If they’d known that, it would have been obviously a good idea.
@layer07_yuxi Some people are just on another level
@layer07_yuxi When I first started learning lisp, all the manuals made a big deal about how the 1980s were such a golden era for AI research. I didn't really understand what they were on about until recently.
@layer07_yuxi Hm very interesting
@layer07_yuxi @a_tschantz What book is it?
@layer07_yuxi @soumikRakshit96 you told me this story few hours ago
@layer07_yuxi Fascinating story makes me wonder if todays breakthroughs come more from patient debugging like Hinton or from sheer compute power?
@layer07_yuxi Like people will look at all the artifacts but think they were investigating the mind.
@layer07_yuxi what paper/book etc is the original quote from? looks interesting
@layer07_yuxi His idea paper 'forward - forward networks" is proof he's still not sold on backprop for efficient learning.
@layer07_yuxi contrastive-divergence does learn really fast and can learn to solve NSAT




@layer07_yuxi Incredible that the Nobel prize was awarded for something that never worked
@layer07_yuxi I think "stack of papers" means research papers on the topic, not printed weights
@layer07_yuxi What is the book?
@layer07_yuxi Do things that don’t scale…
@layer07_yuxi wtf
@layer07_yuxi This Is The Way.