
This is fucking brilliant. Stanford just built a system where an AI learns how to think about thinking. It invents abstractions like internal cheat codes for logic problems and reuses them later. They call it RLAD. Here's the full breakdown:

The idea is brutally simple: Instead of making LLMs extend their chain-of-thought endlessly, make them summarize what worked and what didn’t across attempts then reason using those summaries. They call those summaries reasoning abstractions. Think: “lemmas, heuristics, and
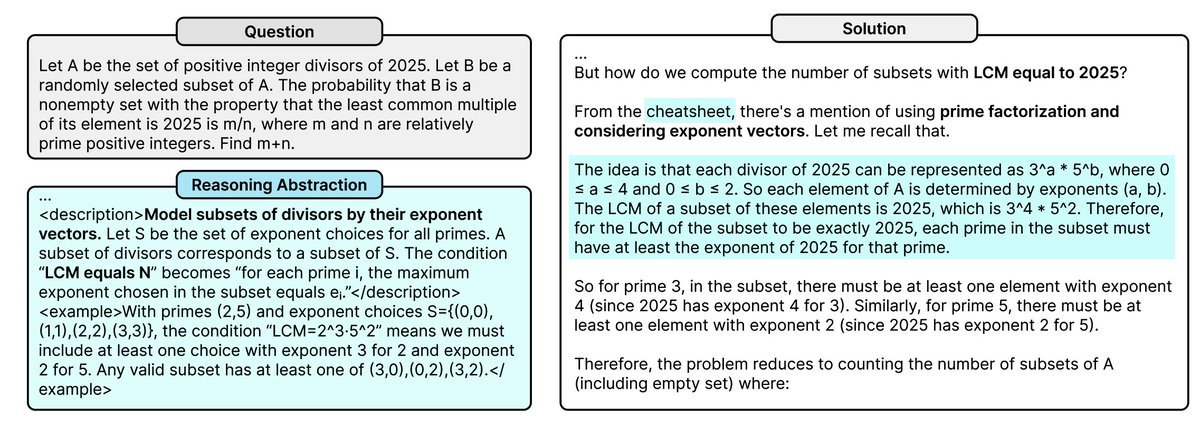
Example (from their math tasks): After multiple failed attempts, the model abstracts: “Check the existence of a multiplicative inverse before using x⁻¹ in a congruence.” Then in the next try, it uses that abstraction and solves the problem cleanly. That’s not prompt

They train two LLMs via reinforcement learning: • An abstraction generator proposes conceptual shortcuts • A solution generator solves the problem using those abstractions The abstraction generator gets rewarded if its ideas actually help the solver perform better. Two
Benchmarks: On AIME 2025, DeepScaleR Hard, and AMC 2023, RLAD beats prior RL fine-tuning (DAPO) by up to 48%. And even when not given abstractions at test time, RLAD-trained models still outperform baselines meaning they internalized that structured thinking. That’s the big

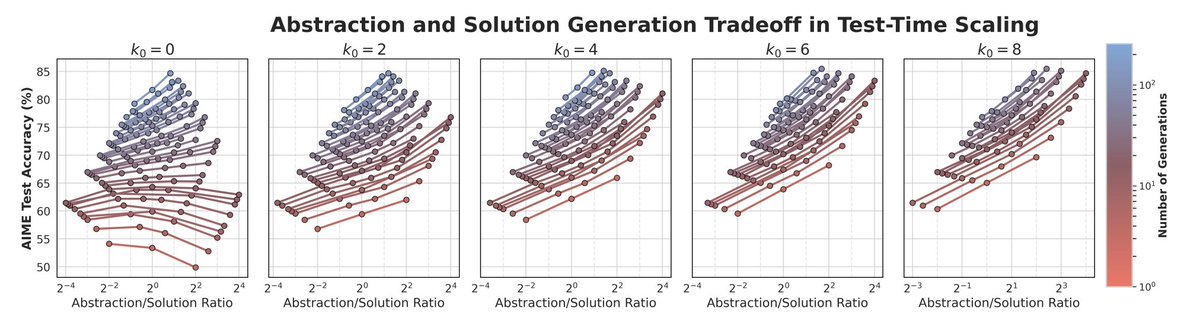
They also studied how to spend inference compute: Should you sample more solutions, or more abstractions? Turns out, once you’ve handled local logic errors, it’s way better to spend compute on generating diverse abstractions not more chains-of-thought. Breadth > depth.
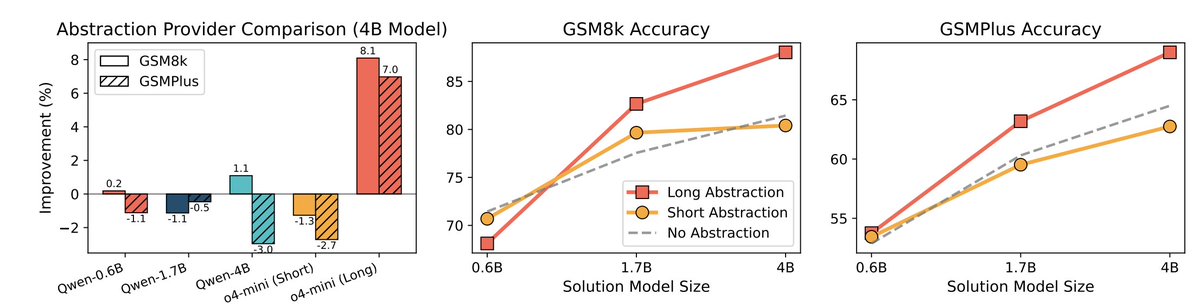
And those abstractions aren’t just fluff. They cluster into types: • Techniques (e.g. “launchpoint lemma”) • Heuristics (“follow the symmetry”) • Caution alerts (common mistakes) They’re like the model’s self-written playbook.
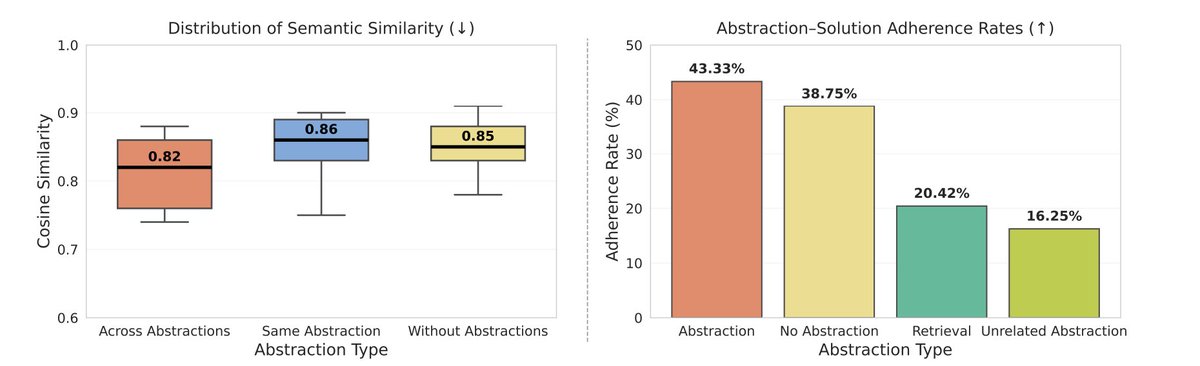
Under the hood, it’s basically a two-player RL game with cooperative objectives each model reinforcing the other’s usefulness. The more an abstraction helps solve new problems, the more the generator learns to make better ones. That’s the first scalable feedback loop for
So what’s next? The authors suggest a future where a single model can both propose and use abstractions mid-reasoning. A kind of self-reflective LLM one that writes its own strategy guide while solving problems. That’s not “thinking longer.” That’s learning how to think.
Full paper: http://arxiv.org/abs/2510.0226... Authors: CMU & Stanford (Salakhutdinov, Finn, Kumar et al.) Project: http://cohenqu.github.io/rlad....
@godofprompt Great share
@lucacoder0 thx
@godofprompt That inverse abstraction example is wild. It’s like the model developed a mathematical gut feeling.
@godofprompt this breakthrough is soon going to revolutionize the process.
@godofprompt Stanford’s new RLAD lets AI literally think smarter
@godofprompt Wow
@godofprompt This might be the most important ML paper of 2025.
@godofprompt @threadreaderapp unroll