
open-source OCR models are super cheap to run and privacy first 🤝 BUT there's a ton of new models out there: DeepSeek-OCR, Nanonets, PaddleOCR, how do you pick them? 🤯 don't worry though, @huggingface got you covered! 🫡🧶

in this blog post, we go through all the how to's ⤵️ > pick a model > compare bleeding-edge ones > deploy (locally/remotely) > go beyond OCR! https://huggingface.co/blog/oc...
@mervenoyann @huggingface And the best model yet just dropped https://x.com/VikParuchuri/sta...
@mervenoyann @huggingface This is insightful!
@mervenoyann @huggingface pure shit only glm is good
@mervenoyann @huggingface I wonder if the Qwen 3 VL models can be seen as an OCR model as well?
@mervenoyann @huggingface Hugging Face simplifies the chaos! Centralizing model evaluation and selection makes choosing the right OCR both cost-effective and privacy-conscious.
@mervenoyann @huggingface this is a godsent. thank you
@mervenoyann @huggingface Awesome for the open-source community 🙌
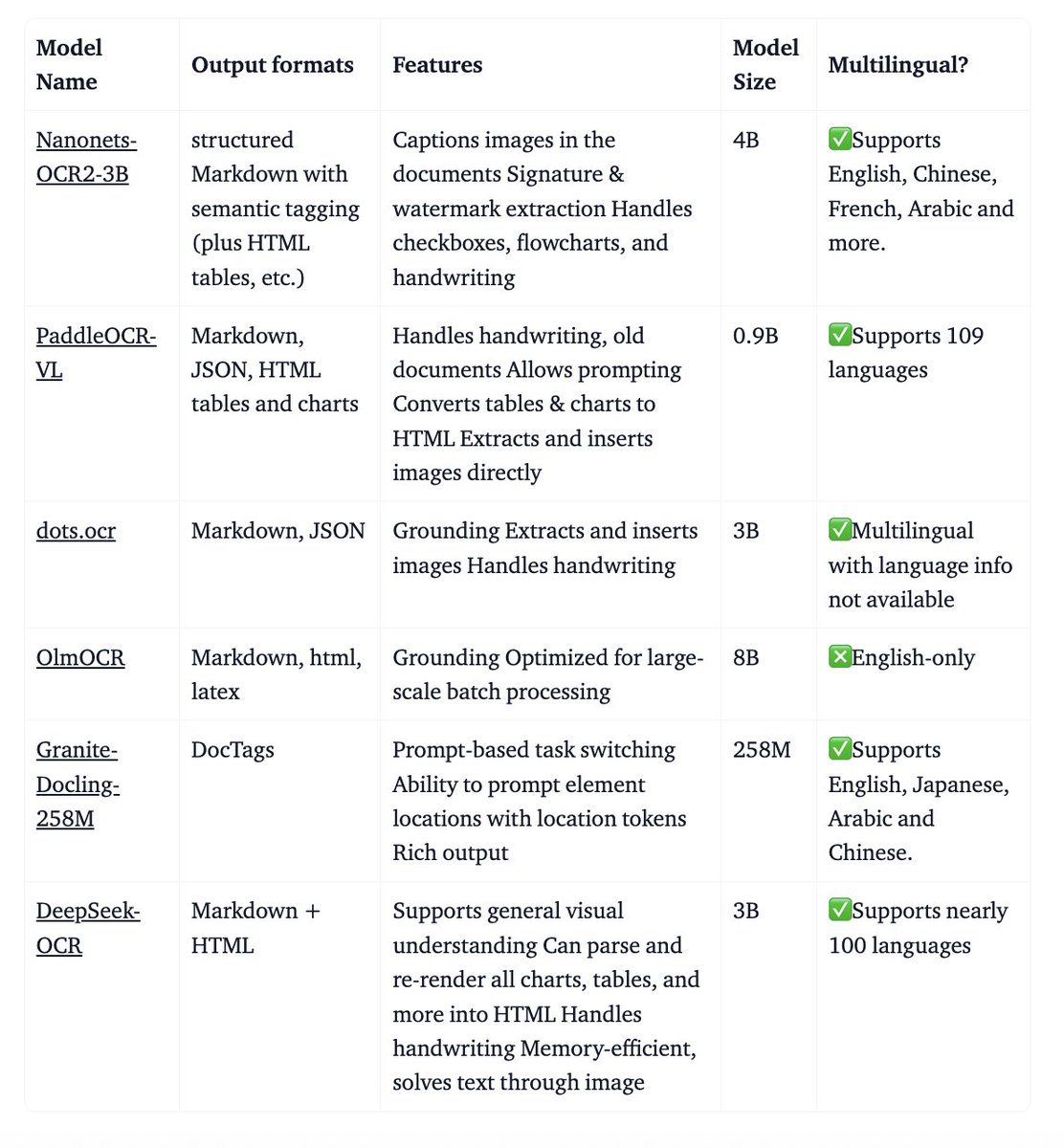
a bunch of OCR models released in past few weeks: ~ deepseek-ocr-3b ~ olmo-ocr-2-7b ~ chandra-ocr-8b ~ nanonets-ocr2-3b ~ paddleocr-vl-0.9B ~ qwen3-vl-dense/moe (general vlm) ~ dots.ocr-3b Will be dropping a detailed comparison soon
Open. Source. SOTA. Deep. Research. 🚀 Today, we’re releasing PokeeResearch-7B, a SOTA open-source deep research agent that outperforms all other 7B deep research agents. And, we are open-sourcing both the weights and inference code on @huggingface! We're additionally excited
DeepSeek OCR processes PDFs at 1/10th the cost of traditional OCR tools We're now hosting it on alphaXiv's API! Extract figures, complex diagrams, and text from any PDF 🚀
after the OCR blog we dropped yesterday people still ask me for the "best" model under the post 😅 we wrote the blog because there's no single best OCR model 🤠 but there is a model best for your use case! so please read the blog 🙇🏻♀️ let us know what you think!

