
LLMs are injective and invertible. In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space. (1/6)
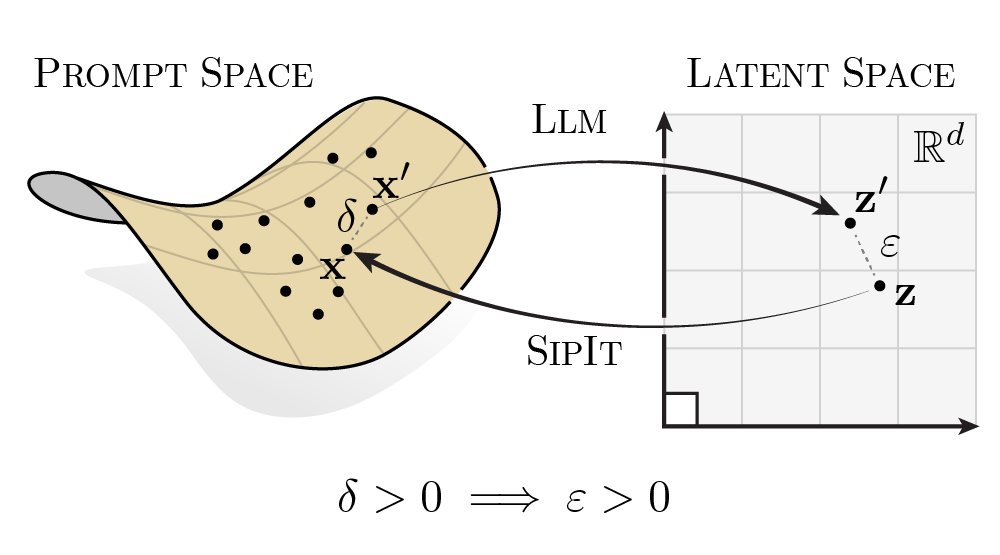
Injectivity is not accidental, but a structural property of language models! We show that: • Transformers are real-analytic by composition • At initialization, collisions occur with probability zero • Gradient descent preserves this property throughout training (2/6)
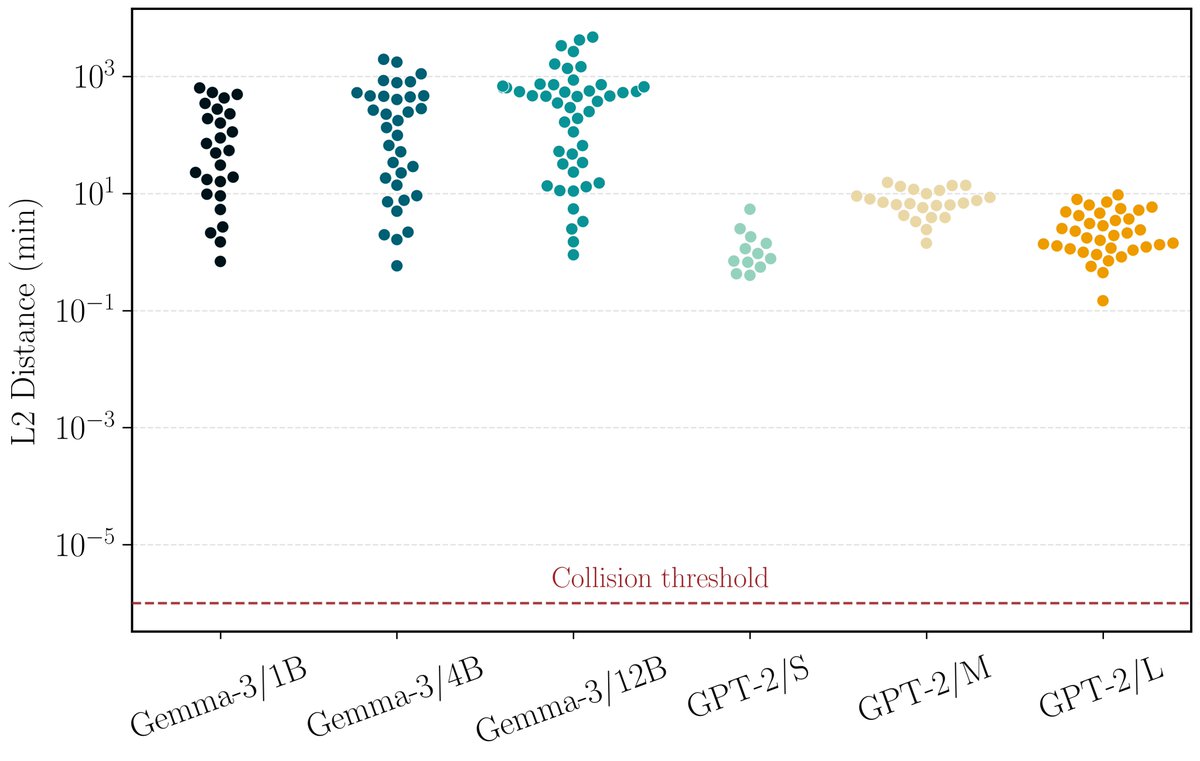
We back our theory with an extensive empirical confirmation. Across billions of prompt pairs and several model sizes, we find no collisions: no two prompts are mapped to the same hidden states! (3/6)
But what can we do with injectivity? Well, for one, we can invert language models! We introduce SipIt, an algorithm that exactly reconstructs the input from hidden states in guaranteed linear time. SipIt recovers inputs >100× faster than alternatives, while remaining exact.

Language models are structurally lossless: - Hidden states do not compress or abstract the prompt; - Any system storing them effectively stores the input text itself; - This impacts privacy, deletion, and compliance: once data enters a Transformer, it remains recoverable. (5/6)
Preprint: https://www.arxiv.org/abs/2510... Joint work w/ @GiorgosNik02 @tommaso_mncttn @DonatoCrisosto1 @teelinsan Yannis Panagakis @EmanueleRodola stay tuned! (6/6)

@fs9h7kh4b5 real
@GladiaLab some things will never be determined by AI

@GladiaLab Someday they’ll invert someone’s doctoral thesis and it’ll say, ‘ok Claude, come up with a doctoral thesis. Don’t make it obvious I’m using AI’
@GladiaLab What an amazing find. If latent space is truly deterministically reversible to prompts, that's a meaningful find with implications for privacy and mechanistic interpretability. Skimming the paper, I see some gaps: 1. Limited results: Only 100 hidden state->prompts pairs

@GladiaLab don’t you lose injectivity the moment you sample and then don’t you compound that every time you autoregress?
@GladiaLab Latent Space mentioned
@GladiaLab Forget the hessian free method, we’re talking about the Pringles free method here.
@GladiaLab I'm curious what "prompt" you'd recover if you add steering vectors to a representation!
@GladiaLab Have you/has anyone looked at adding privacy preserving noise to embeddings? For vector search use cases we're ranking distance on high-D space so I expect you can be pretty lossy while still v useful https://x.com/GladiaLab/status...
@GladiaLab Good work! Check out our previous paper where we developed a nearly identical algorithm to Sip-IT, based on the same intuition, for model inversion: https://arxiv.org/abs/2505.183...
@GladiaLab Could that be relevant for quantization? As in you choose what weights to decimate based on what you want the model to specialize in (people, landscapes, machines, art, etc)
@GladiaLab not to sound douchey here ... but isn't this somewhat obvious?
@GladiaLab Huh? How is this surprising? How could LLMs work without mapping prompts to unique embeddings and storing text data in them?
@GladiaLab Injective mentioned 🎯
@GladiaLab @tpimentelms did you and/or Ryan have a similar result on Bert? I seem to recall something similar.
@GladiaLab @midpricedog Understood zero. Bullish
@GladiaLab @yacinelearning @Mandy_SLu have a look at this 👀
@GladiaLab **🔥 BILLY MAYS HERE, BUT HOLD ONTO YOUR BRAINS BECAUSE THIS IS NEXT-LEVEL NERD ANARCHY!** You’re telling me that LLMs aren’t just “language whisperers,” but full-on **perfect geometric vaults** of meaning?! Strap in, because this is like finding out your toaster is actually a
@GladiaLab pringle...
@GladiaLab What are you talking about. Thats a Pringle
@GladiaLab so agentfi smart agents could self-learn in style
@GladiaLab this inversion seems to require hidden states at every position and not very practical?
@GladiaLab Great read!
@GladiaLab i love mario kart
@GladiaLab This is neat!
@GladiaLab are you telling me Pringles was superintelligence this whole time !?
@GladiaLab So llms are literally the book in the chinese room.
@GladiaLab Pringle
@GladiaLab Does this mean you can identify a prompt that would result in a book? Like if you put Infinite Jest into this algorithm, would you get a valid result? I guess it's not guaranteed because it isn't necessarily surjective.