
DGX Spark appears to be maxing out at only 100 watts power draw, less than half of the rated 240 watts, and it only seems to be delivering about half the quoted performance (assuming 1 PF sparse FP4 = 125 TF dense BF16) . It gets quite hot even at this level, and I saw a report
@ID_AA_Carmack >(assuming 1 PF sparse FP4 = 125 TF dense BF16) Why did you assume this? Nvidia's own RTX Blackwell whitepaper shows that, with FP32 Accumulate, 1 PF sparse FP4 = 125 TF sparse BF16 or 62.5 TF dense BF16. It's an RTX part, not RTX PRO. The equivalent of a 5070. RTX parts are
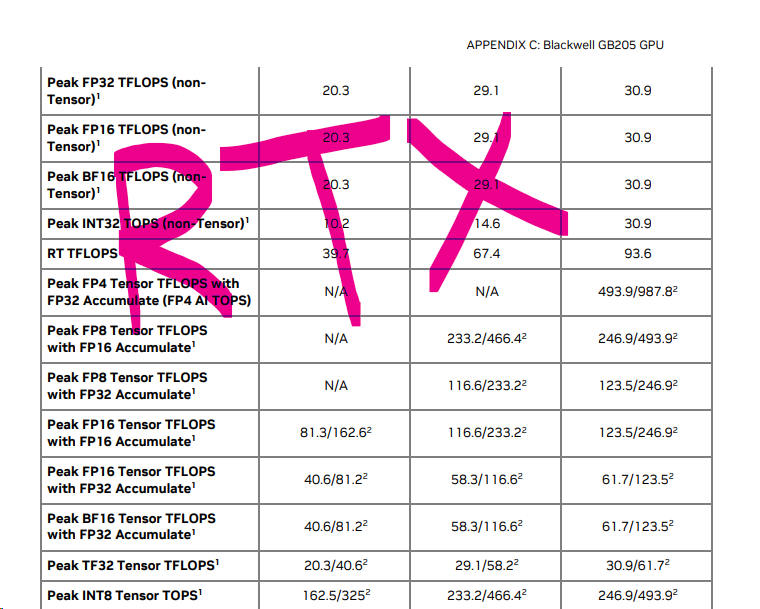
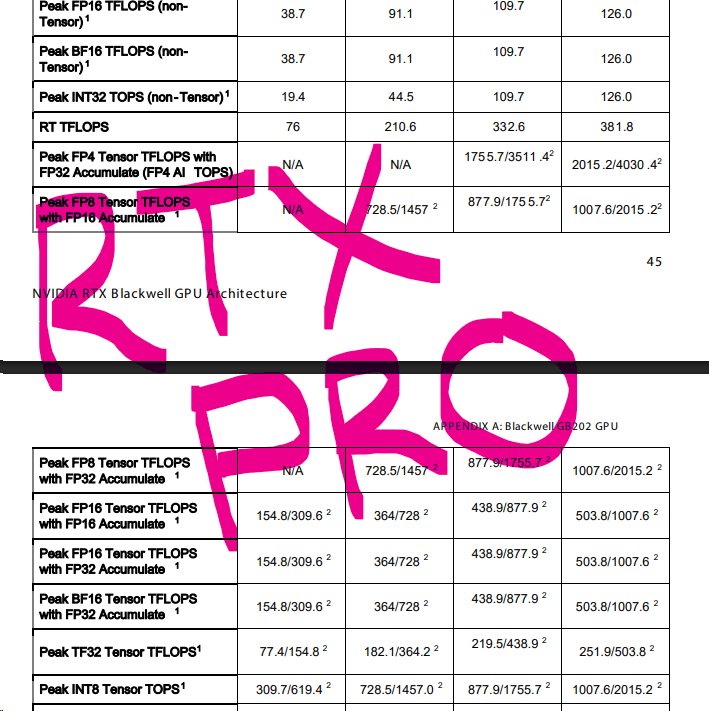
@Lasurak Well, that may explain it… I didn’t know there was another 2x boost between the marketing number and the numbers I care about.
@ID_AA_Carmack I've microbenchmarked torch and MLX which both route to cuBLAS. They both only get ~60 TF at bf16 for nice large square matrices. I'm not sure if it's the machine or the implementation which is suboptimal.. but I was expecting higher. Here's the benchmark: ``` import time
@awnihannun That is what we are seeing. Seems about right if it is only drawing 100W instead of 200W+.
@ID_AA_Carmack From an internal briefing I attended with Dell, they said their Pro Max with GB10 cooling solution was going to be better than Nvidia's first party solution and the performance and power would be a bit higher. I don't have units to compare, but this was directly stated. 1/
@ID_AA_Carmack Another issue with DGX Spark is NVIDIA GB10 (CUDA 12.1) unsupported by PyTorch (min 8.0, max 12.0).
@ID_AA_Carmack I'm using one daily and its output in token per second seems to be about a third of MacStudio M3 Ultra (6 tok/s vs 18 tok/s with Qwen2.5vl 32b param, 8bit quant with Ollama).
@ID_AA_Carmack In a multi unit workload the NVLink NIC will eat some too.
@ID_AA_Carmack As predicted Nvidia is at the end of the road in terms of thermal capacity. It will take them 30 years to climb out like it did for Apple. Apple had heat problems with IBM and the G5 chip. Then Intel x86. Apple Silicon was scratch built out of necessity. Apple will win the war.
@ID_AA_Carmack I don’t understand why it had to be THAT small. I mean compact is nice, but nobody would care if it was twice the size and had proper, reasonably quiet cooling.
@ID_AA_Carmack I mean did we ever think they were going to meaningfully cannibalize their money maker with a useful piece of hardware for <5k?
@ID_AA_Carmack Who would have thought that Apple would have produced the best local AI inference hardware, with the worst software deployment of all major tech companies.
@ID_AA_Carmack It's only rated for 170W, not 240W - the 240W number was a misstatement by an employee at GTC, it was never official - and it looks like they've left the GeForce fp32-accumulate nerf enabled lmao
@ID_AA_Carmack what hardware would you recommend for similar workloads instead?
@ID_AA_Carmack DGX Spark's power reality check. 100W instead of 240W, half the performance. Hardware evolution isn't linear - it's a complex dance between engineering ambition and thermodynamic constraints. 🔌🧠 #AIInfrastructure
@ID_AA_Carmack nvidia marketing team sweating trying to explain why their $25k mini pc performs like a $500 used gpu
@ID_AA_Carmack Have you played around with Strix Halo much?
@ID_AA_Carmack can you tell when it was manufactured or if it is a dev kit? maybe needs some firmware updated
@ID_AA_Carmack Oh, so you wanted it water cooled for $4K?
@ID_AA_Carmack Software update needed?
@ID_AA_Carmack interesting news
@ID_AA_Carmack I bought one just to have a cool little Linux machine on my desk, knowing the limitations on memory bandwidth, etc. It has already rebooted itself under load. Thought it was an update but automatic updates are off. Have not run benchmarks but now I’m curious.
@ID_AA_Carmack Time to splatter on 2 kilo copper heatsink and re test the thermal throttles.
@ID_AA_Carmack Thermal throttling. Same thing happens on the smaller Jetson boards - turn off the power limit, and you'll get inconsistent model benchmarks that wander around.
@ID_AA_Carmack The power draw being so low but still causing heat issues suggests a thermal inefficiency in the system. If it’s not even hitting the rated performance with half the power, it’s fair to ask whether it was de-rated before launch for stability reasons.
@ID_AA_Carmack Does it perform better with a giant fan slapped onto it?
@ID_AA_Carmack For most Nvidia GPUs (I guess) you can save 30% power draw at only 5% speed loss, see https://github.com/xor2k/gpu_u...
@ID_AA_Carmack John great question, we are still waiting for ours, but you can do a few quick test to validate something else isn't holding it back. Start this monitor: watch -n 1 nvidia-smi --query-gpu=power.draw,http://clocks.sm,clocks.mem,te... --format=csv then kick off
@ID_AA_Carmack I don't know how a GB10 would be getting anywhere close to 100+ TFLOP/s bf16 when that's a substantial portion of what a RTX 6000 is supposed to get with ... 3-4x cuda-core/die-size and 3x+ power? Getting straight, non-BS-sparse-factored answers from Nvidia is a challenge.
@ID_AA_Carmack Sounds defective.
@ID_AA_Carmack Oh!
@ID_AA_Carmack As a hardware weenie who just wants a quiet network device to run PyTorch on, I’m not complaining. It may be more consumer friendly than being a technological triumph.
@ID_AA_Carmack Half the power draw, half the performance, twice the heat. Sounds like a feature, not a bug, in this economy. Guess they optimized for the benchmark marketing slide instead of sustained compute. Ship first, debug on mainnet. The Silicon Valley way.
@ID_AA_Carmack You should try the latest docker-image below and use tensor-rt for the optimized CUTLASS speedups, but yes it's disappointing https://catalog.ngc.nvidia.com...
@ID_AA_Carmack Is the GPU idle temp higher than it should be? I’ve lost H100 GPUs and that’s the first sign. I suspect a heat sink issue caused them to overheat and eventually die.
@ID_AA_Carmack You can't run bfloat16 on a single one of those tiny boxes John