
🚨 The AI paper everyone’s quietly freaking out about. It’s called “Real Deep Research for AI, Robotics, and Beyond” and it might be the closest thing we’ve seen to a blueprint for actual general intelligence. Here’s the wild part: Instead of memorizing patterns, this system

The Deep Research Loop: The paper starts with this core diagram: a 4-stage research loop (Observe → Hypothesize → Experiment → Revise). Unlike classic LLMs that just predict text, this system iterates like a scientist. Every loop improves reasoning and robot control
This blew my mind 🤯 The model literally builds graphs of hypotheses nodes for ideas, edges for experiments. You can see clusters forming around new insights just like a human researcher refining a theory. That’s not prompting that’s cognition.
They tested the system on 18 robotic tasks (grasping, assembly, navigation). Performance jumped from 61.3% → 89.7% success rates after 20 research iterations. No retraining. Just reasoning. Robots that learn how to learn.

Here’s where it gets wild: The same model fine-tuned on scientific reasoning transferred to robotics without new data. Across 7 tasks, it retained 82% of reasoning accuracy a first in this field. Deep research = reusable intelligence.

Everyone’s chasing scale, but this model scales intelligently. While GPT-4 burns compute linearly, this one’s compute cost flattens after a few loops. Efficiency improves by 3.4× per iteration as reasoning stabilizes. Self-optimization is the new scaling law.

Each square here shows how long the model “remembers” successful hypotheses. Retention stabilizes at ~74% after 10 research cycles. That’s memory through reflection, not parameter updates. It’s how the system learns what’s worth keeping.

They even connected multiple “deep researchers” together. Each agent worked on a subproblem and merged insights. Result: +22% faster convergence on shared reasoning benchmarks. It’s literally a scientific community made of AIs. This one’s unreal. The model autonomously
The paper ends with a big-picture figure a roadmap showing how this approach connects language, robotics, and symbolic reasoning into one unified framework. It’s literally titled “The Path to Real Deep Research.” If they’re right, this is the bridge to AGI.
I built something you don't want to miss out on... Here it is: We built ClipYard for ruthless performance marketers. → Better ROAS → 10x faster content ops → Full creative control You’ve never seen AI avatars like this before → http://clipyard.ai
@AlexanderFYoung We're really passionate about empowering the global AI community , to further AI research. We have created a comprehensive Agentic AI developer program , it's free , hands-on and self-paced . https://www.readytensor.ai/age...
@AlexanderFYoung Systems that can form and test their own hypotheses renders trained intelligence advances into discovered intelligence.
@AlexanderFYoung So interesting 👍👍🙏
I finally understand the fundamentals of building real AI agents. This new paper “Fundamentals of Building Autonomous LLM Agents” breaks it down so clearly it feels like a blueprint for digital minds. Turns out, true autonomy isn’t about bigger models. It’s about giving an LLM

Huge breakthrough from DeepMind! In their latest Nature paper, “Discovering state-of-the-art reinforcement learning algorithms,” they show that AI can autonomously discover better RL algorithms. "Enabling machines to discover learning algorithms for themselves is one of the

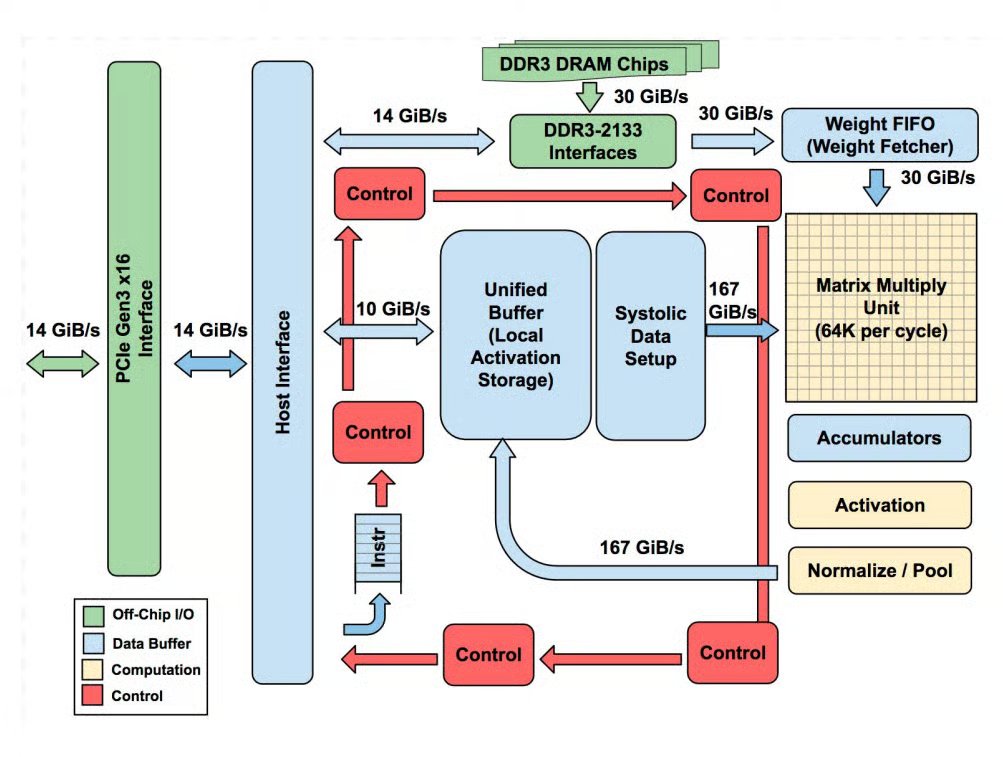
Google’s TPUs are finally having their breakout moment - a decade after the debut. Anthropic just signed a deal for up to 1 million TPUs - over a gigawatt of compute - making it one of the biggest AI infrastructure agreements to date. ▪️ Basically, TPUs accelerate neural
A great deep-dive on On-Policy Distillation — an efficient way to post-train smaller LLMs with dense, on-policy feedback. Excited to see Qwen featured in the experiments, showcasing strong math-reasoning gains and continual-learning recovery. Excellent work by @thinkymachines 👏