
After ~4 years building SOTA models & datasets, we're sharing everything we learned in ⚡The Smol Training Playbook We cover the full LLM cycle: designing ablations, choosing an architecture, curating data, post-training, and building solid infrastructure. We'll help you

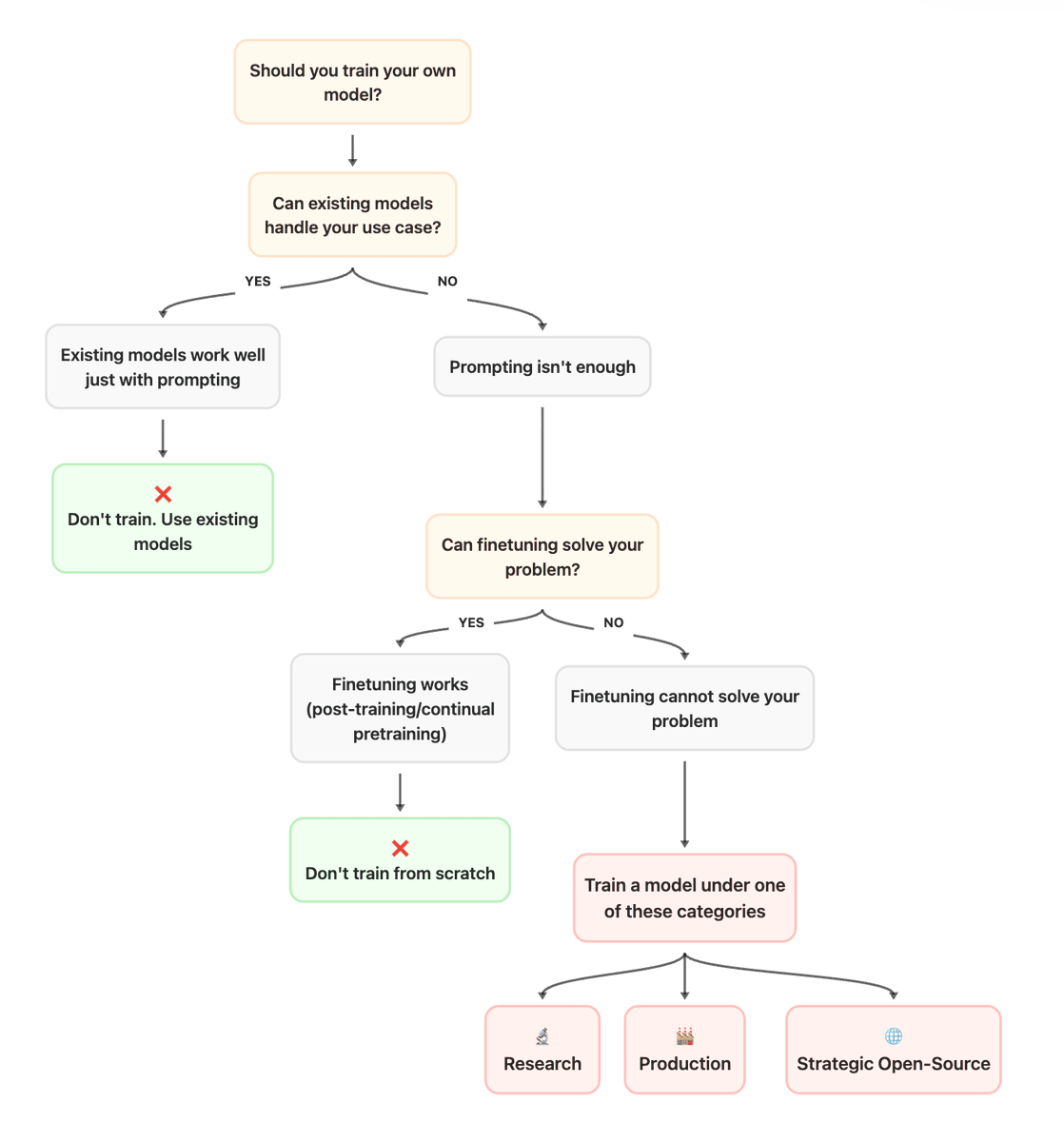
1/ In the first two chapters, we help you decide if you really need to train from scratch and set up your ablations: - Choosing your training framework - Selecting reliable evals - The art of derisking ✨
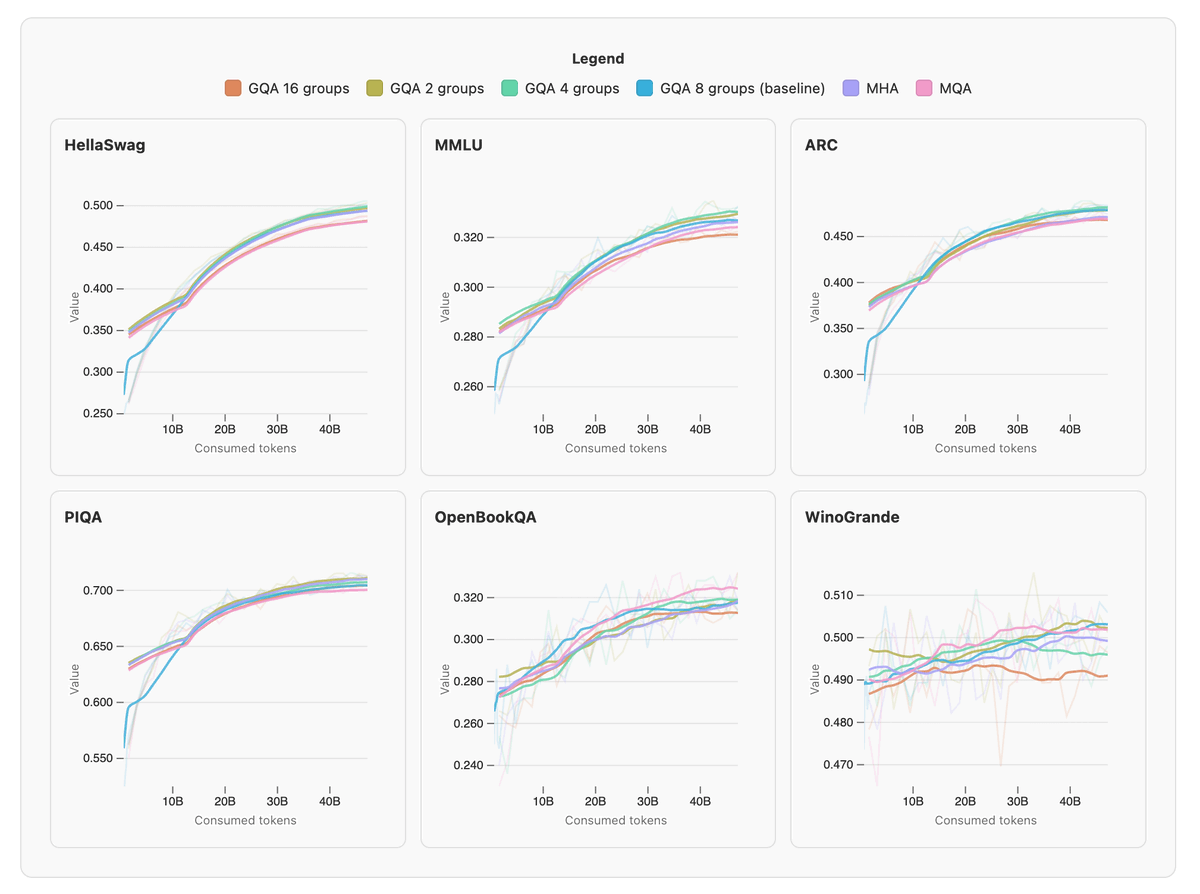
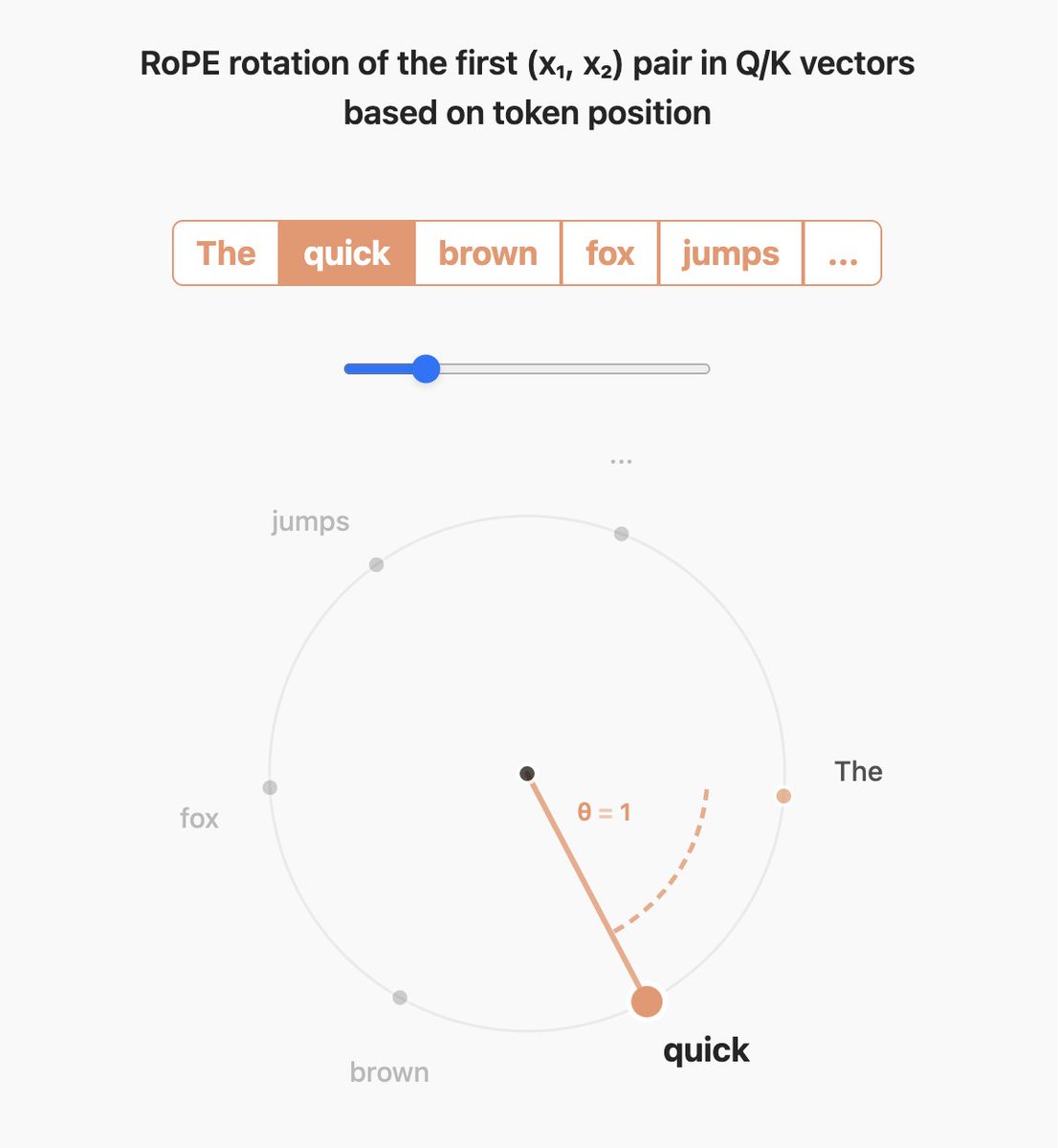
2/ Next, we go over model architecture with 20+ ablations testing each transformer component: - Attention: MHA, GQA, MQA, MLA - RoPE, NoPE, IntraDoc Masking, SWA - MoEs & Hybrid models overview - Tokenizers - Optimizers and hyperparameter tuning
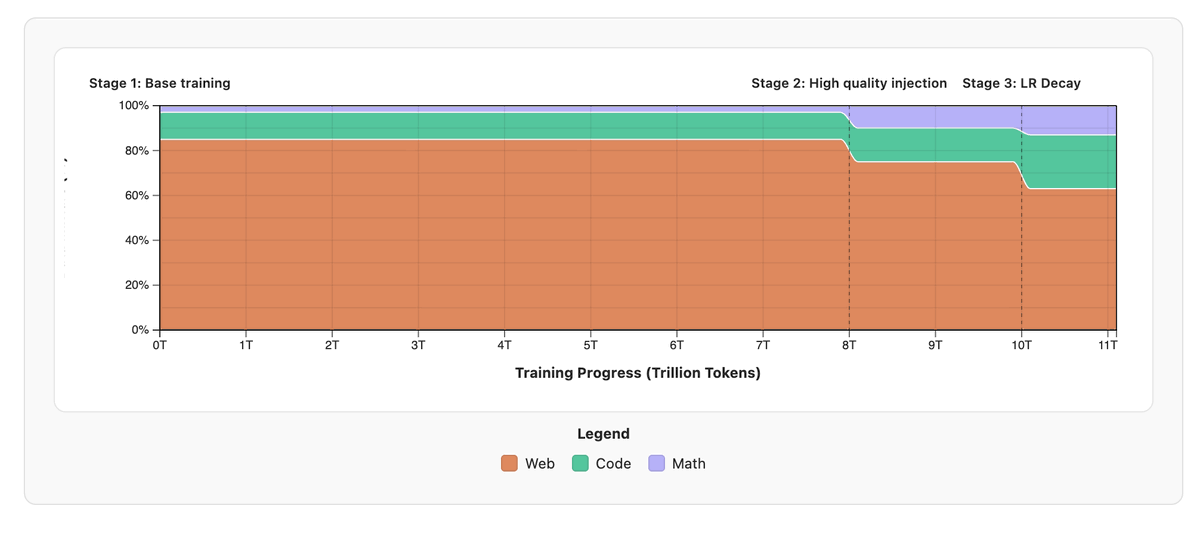
3/📚 We then cover the secret sauce: data ! - History of scaling laws - How to curate and mix datasets - Building training curricula to push performance
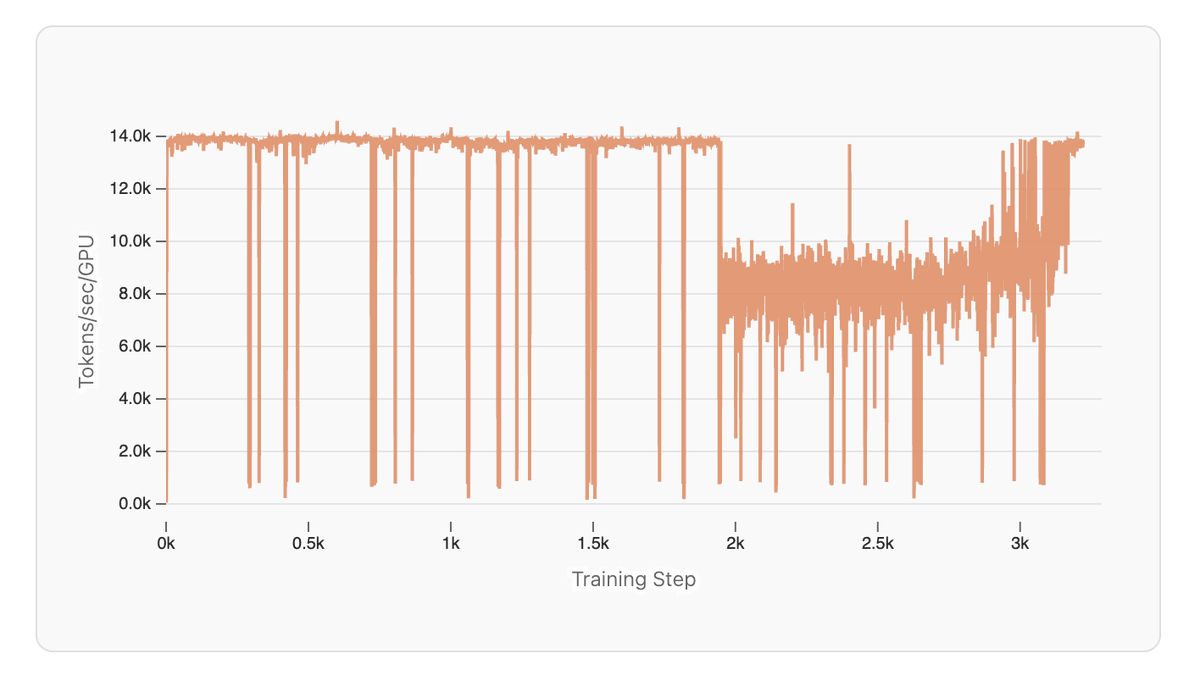
4/ Next is the training marathon, where things might not go as planned. We show how we debugged SmolLM3's vanishing throughput and share best practices for handling the surprises that emerge at scale (including a sneaky bug that forced us to restart the run at 1T tokens!).
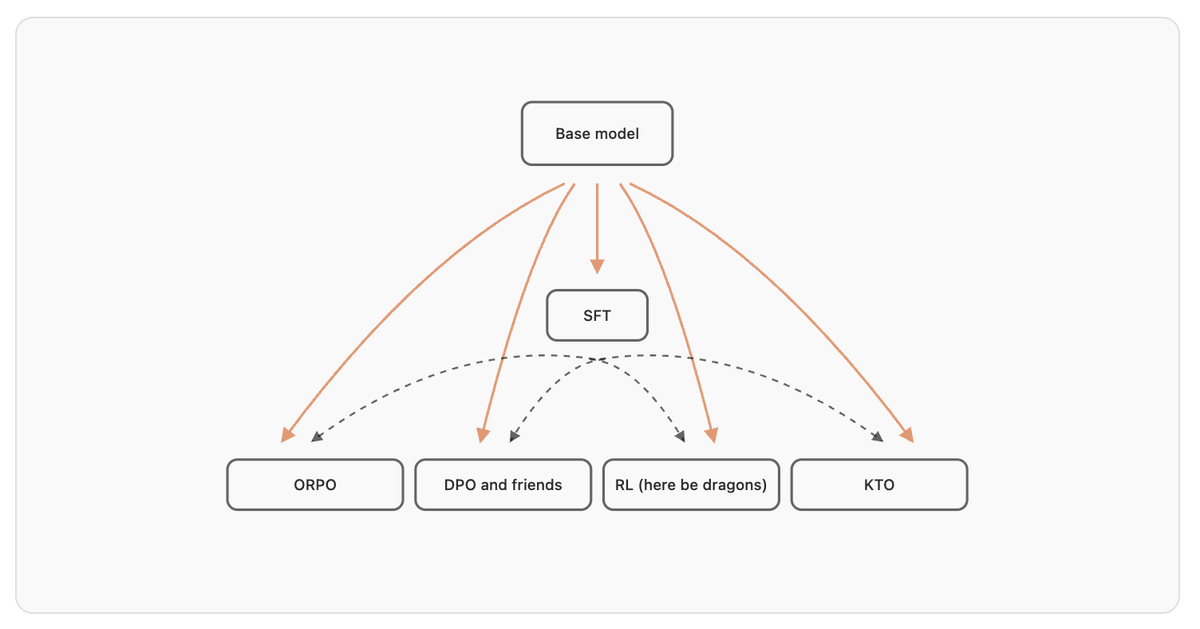
5/ Post-training 2025, turning base models into useful assistants: - Setting up SFT baselines - When to do RL - We apply GRPO to double SmolLM3's math perf
6/ Finally, the often-overlooked infrastructure: GPU fundamentals, CPU/GPU/nodes/storage communication patterns, parallelism strategies, and debugging NCCL errors & cluster bottlenecks 🔧

We hope you enjoy this read! Link: https://huggingface.co/spaces/...

@LoubnaBenAllal1 Woohoo, it's finally out! Reading your chapters made me realise how much more hardcore pre-training is than post-training 😆
@_lewtun hahah you'd be less optimistic if you did pretraining 🙈
@LoubnaBenAllal1 @Thom_Wolf Amazing! Congratulations and thank you to the team @LoubnaBenAllal1
@hughesthe1st @Thom_Wolf Thanks Sean!
@LoubnaBenAllal1 such beautiful charts 🤗
@RaphaelKalan Thanks
@LoubnaBenAllal1 i was JUST thinking that you or @eliebakouch should drop a playbook for smol models. Cant wait to read this!!!
@garrxth @eliebakouch enjoy!!
@LoubnaBenAllal1 hello loubna have you ever heard about muon?
@eliebakouch from someone who calls people using Adam "lazy"

@LoubnaBenAllal1 Does it include dataset streaming from HF already ? :p
@lhoestq soon
@LoubnaBenAllal1 what were the biggest surprises or counterintuitive findings during those four years that most people building models still get wrong? anything about data curation specifically?
@LoubnaBenAllal1 Is this only available via the space? -it's not loading for me
@LoubnaBenAllal1 How to buy a hard copy of this book?
@LoubnaBenAllal1 Kas čia toks žviegė
@LoubnaBenAllal1 Looks like a huge piece of work, congrats!
@LoubnaBenAllal1 That's a fantastic initiative, Loubna! Sharing your learnings on LLMs is truly valuable, especially for those getting started, right?
@LoubnaBenAllal1 Can we get a pdf ?
@LoubnaBenAllal1 Justo lo que necesitamos: experiencia real, visualizaciones claras y hasta el 'yolo run' de rigor. Mejor que muchos papers. ¡Esto empuja la IA de verdad!
@LoubnaBenAllal1 Good to see a playbook covering the full LLM lifecycle.
@LoubnaBenAllal1 This is amazing. Thank you.
@LoubnaBenAllal1 Wohoo 🎉
@LoubnaBenAllal1 Brilliant work 👍
@LoubnaBenAllal1 the all-in-one guide you need for pre-training 👌
@LoubnaBenAllal1 This RoPE visualization is amazing
@LoubnaBenAllal1 Thank you for sharing!