
What if next-token prediction wasn't a single forward pass, but a tiny optimization problem? Introducing: nanoEBM a tiny transformer that learns to think harder by doing gradient descent on its own predictions. You can start training on your Mac now - it comes < 400 lines
A few days ago I wondered if LMs could think harder without CoT prompting but by doing gradient descent on some objective function - this led me to energy-based models[1] where you learn some smooth and differential function to find a good y for any x. [1]
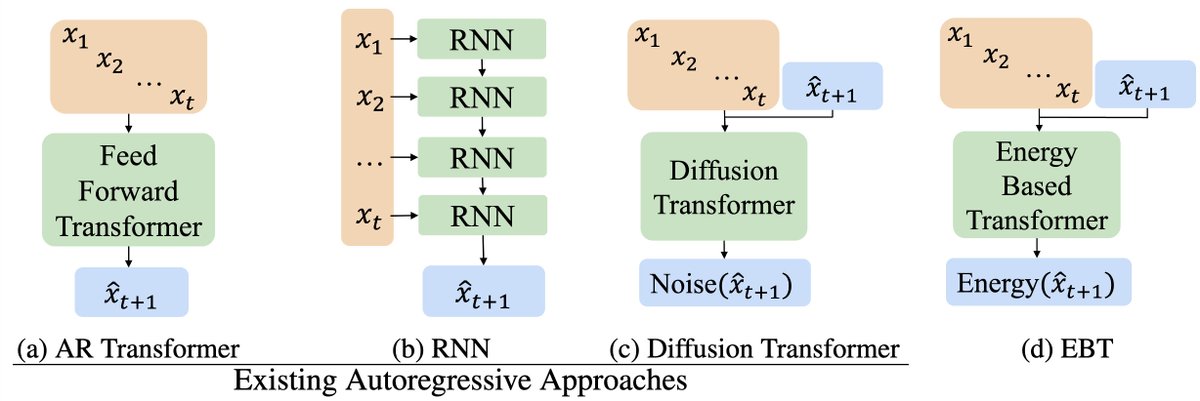
The core idea is to learn a E(x,y) where "low energy" is text we want and vice versa. During inference we get a prediction from the LM, compute its energy, take a gradient step to find a better prediction until we find a better answer without additional forward passes. In theory
Ok, but aren’t we just learning our dataset? E can be anything so we need use MC-sampled negatives (contrastive divergence) to approximate the gradient; pushing energy down on data, up on our samples. Because the model’s unnormalized(important later), computing E is exponentially

nanoEBM is a tiny, from-scratch, ~10M-param char Transformer (67 vocab, 6 layers, 384 dim, 6 heads) with a linear energy head. Its based off @karpathy's minGPT with an additional 400 lines for our EBM. Next-token prediction is a tiny optimization where we compute energies per


On simple tasks like char-level Shakespeare I found it did assign low energy for real data and create a smooth landscape to minimize energy. However the data was too simple, was trained for too short, and our model size was too tiny to find marginal improvements in perplexity

nanoEBM runs on your mac/GPU easily, implemented minimal/extensibly in < 400 lines. A nice property of EBMs is you can combine multiple energy functions (product of experts) and normalize to get a usable distribution. Curious what people will train and merge! Also big

@sdand pre sleep read type shi
@sdand surya strikes again
@sdand super cool
@sdand nice work dude! this is cool!
@sdand https://en.wikipedia.org/wiki/... might be a naive question: is this basically an implementation of predictive coding?
@sdand Looks interesting! It reminds me of this recent paper Reasoning with Sampling that uses MCMC to target a power distribution of the global token sequence. Seems similar at a high level https://www.arxiv.org/abs/2510...
@sdand I thought energy-based transformers have already been release? https://arxiv.org/html/2507.02...
@sdand so less a forward pass more a forward struggle
@sdand This is still unrolling auto-regressively… why not go the whole way and generate in parallel with an EBM? (or a diffusion model) 🤔
@sdand nice. https://github.com/falseywinch... maybe some of these ideas can help take it to the next level? you may like.
@sdand sick! Now u get to fight the hf pretraining novel for top of my reading list
@sdand the theory behind it is this → https://doi.org/10.5281/zenodo...
@sdand AI just got a workout routine. Instead of blurting the next word, it now pauses to think, sweats a little, and optimizes mid-sentence. It’s like giving your laptop a conscience and a caffeine boost.
@sdand Can we not try on our PC as well?
@sdand I'm not sure this could replace reasoning chains... Besides, what's the comparable size of a vanilla Transformer AR model compared to an EBM based on inference speed?
@sdand Is this an implementation of https://arxiv.org/abs/2507.020... ?
@sdand 👌
@sdand What if transformers could optimize their own predictions?