
🌀New paper on the generation phases of Flow Matching http://arxiv.org/abs/2510.2483... Are FM & diffusion models nothing else than denoisers trained at every noise level? In theory yes, *if trained optimally*. But in practice, do all noise level matter equally?
In practice, training a denoiser involves design choices: the parametrization (velocity as in FM, residual Ɛ as in diffusion, or standard denoiser?) and the loss weighting, each influencing the generation quality.

Different loss weightings favor different times: which temporal regime drives the generation quality? Controlled perturbations reveal: drift type effects at early times (& good FID) and noise type at late times (& bad FID)
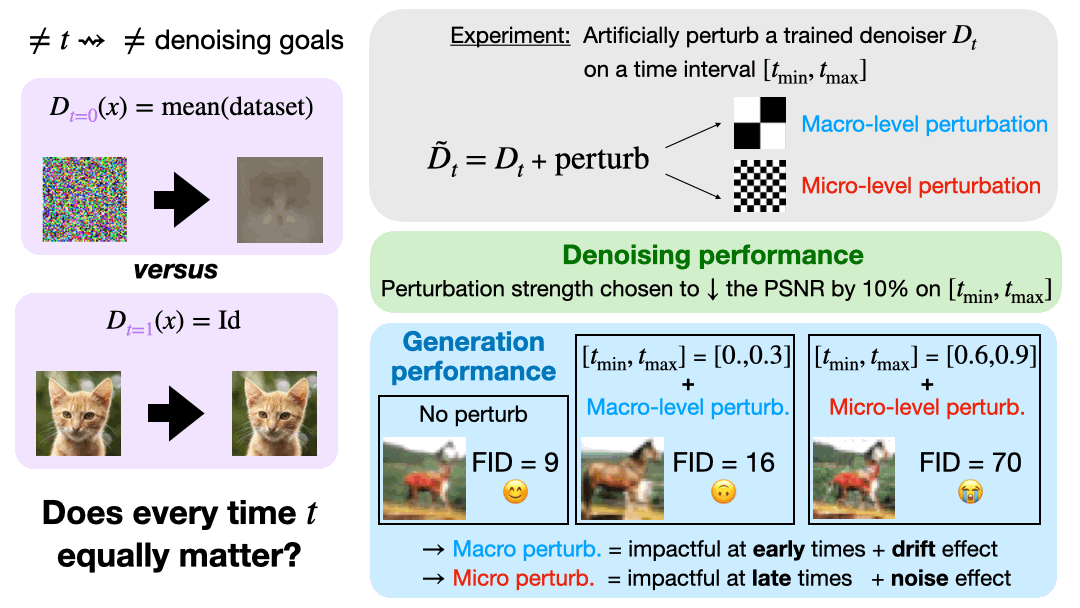
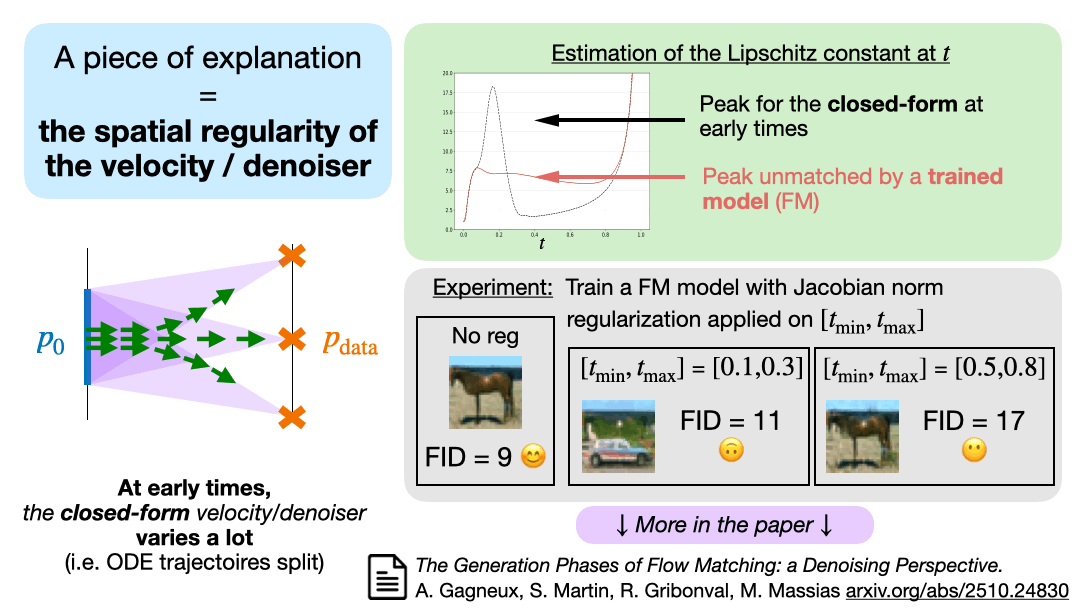
To understand these phenomena, we study the spatial regularity of the velocity/denoiser over time: we observe a gap between the closed-form and trained model. Applying Jacobian spectral regularization, we recover effects seen previously on perturbed denoisers (drift vs noise).
@mathusmassias So what is your impression? Can I just train a flow matching model on a single noise level? And can I recover good quality generations if I use same noise level during inference?
@mathusmassias Diffusion models are like therapists for noise; they patiently remove chaos one layer at a time. Flow Matching just skips the small talk and heads straight to clarity. Not every noise level needs equal attention; some confusion is easier to clean than others.
@mathusmassias Mathurin, that's a brilliant question, and you've hit the nail on the head regarding optimal training.
@mathusmassias I generally prefer to think in terms of less friction, fluidity.
Mapping LLMs with Sparse Autoencoders https://pair.withgoogle.com/ex... An interactive introduction to Sparse Autoencoders and their use cases with Nada Hussein, @shivamravalxai, Jimbo Wilson, Ari Alberich, @NeelNanda5, @iislucas, and @Nithum

I highly encourage anyone interested in Delta Attention/Deltanet to read through this whole thread. You can see how I start from practically 0 and am trying to understand Kimi Delta Attention and related linear attention literature by spamming Grad with questions.

Our paper "Vision Transformers Don't Need Trained Registers" will appear as a Spotlight at NeurIPS 2025! We uncover the mechanism behind high-norm tokens and attention sinks in ViTs, propose a training-free fix, and recently added an analytical model -- more on that below. ⬇️
There will soon also be a PSA of why muon is not a second order optimizer and how all the fancy manifold math is irrelevant. I am sick of people using math intimidation to make their methods sound fancy to bs VCs.