
This paper from Harvard and MIT quietly answers the most important AI question nobody benchmarks properly: Can LLMs actually discover science, or are they just good at talking about it? The paper is called “Evaluating Large Language Models in Scientific Discovery”, and instead
Most AI benchmarks test answers. This paper tests the process of discovery. Models must: • Form hypotheses • Design experiments • Observe outcomes • Update beliefs • Repeat under uncertainty That’s real science, not Q&A.
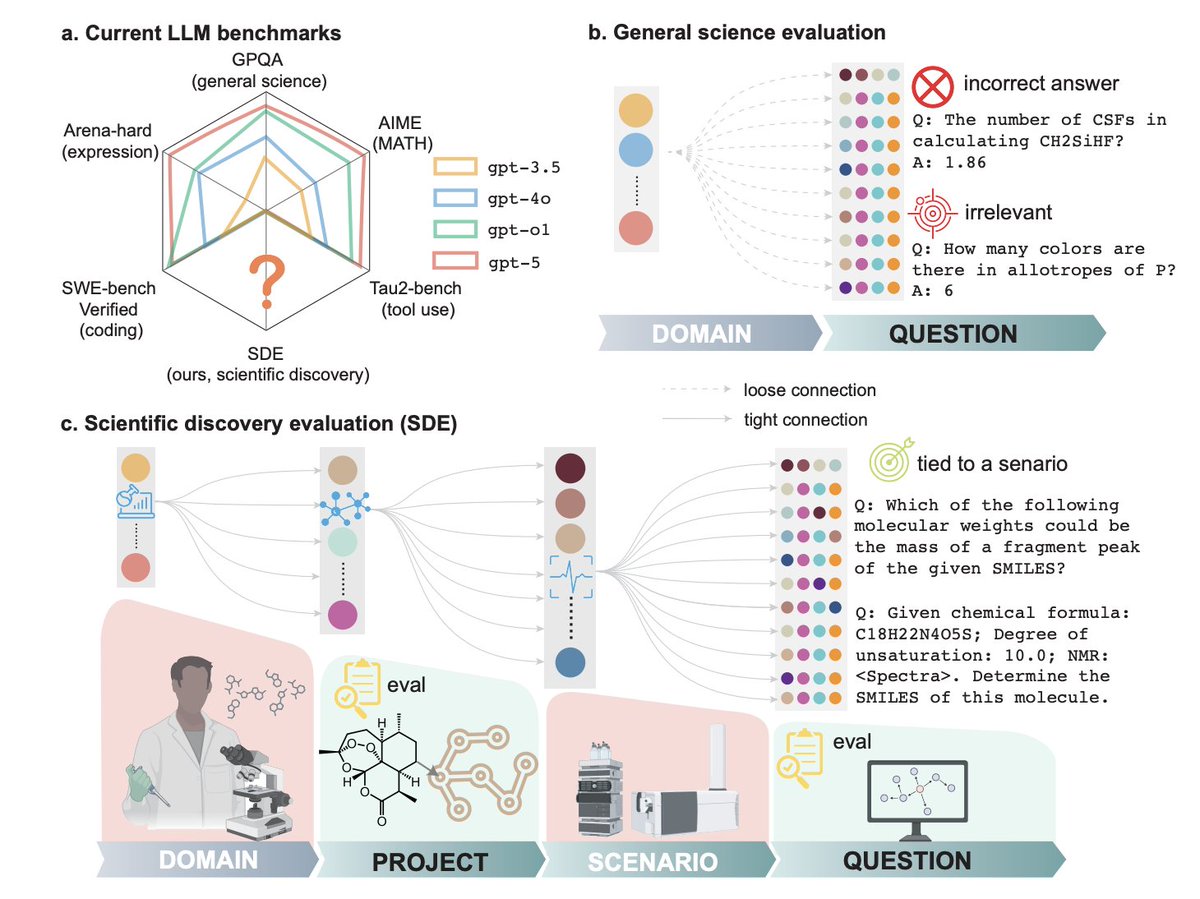
LLMs are surprisingly good at the first step. They generate plausible, well-worded hypotheses that look exactly like something a researcher would write. But that’s where the illusion starts.
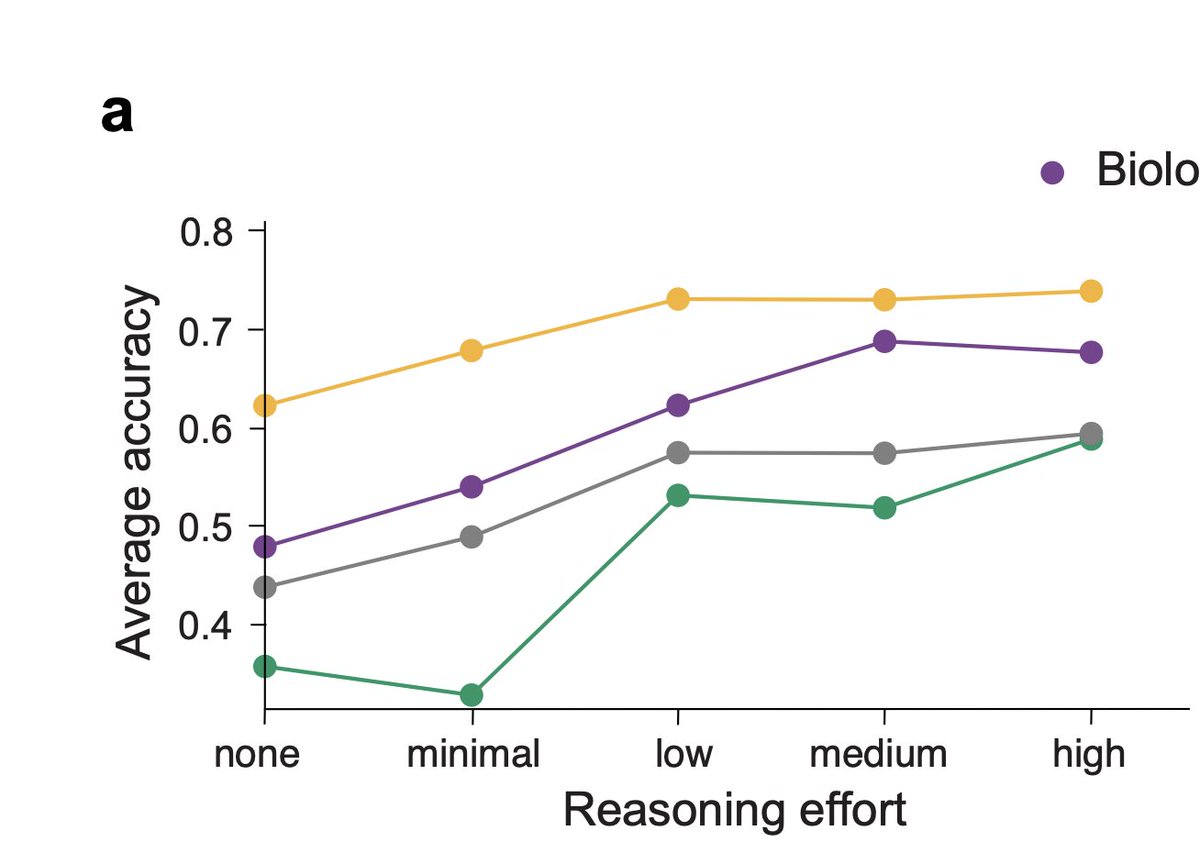
Once experiments produce results, models struggle. They: • Ignore contradictory evidence • Stick to wrong theories • Rationalize failures instead of correcting them They don’t update they defend.
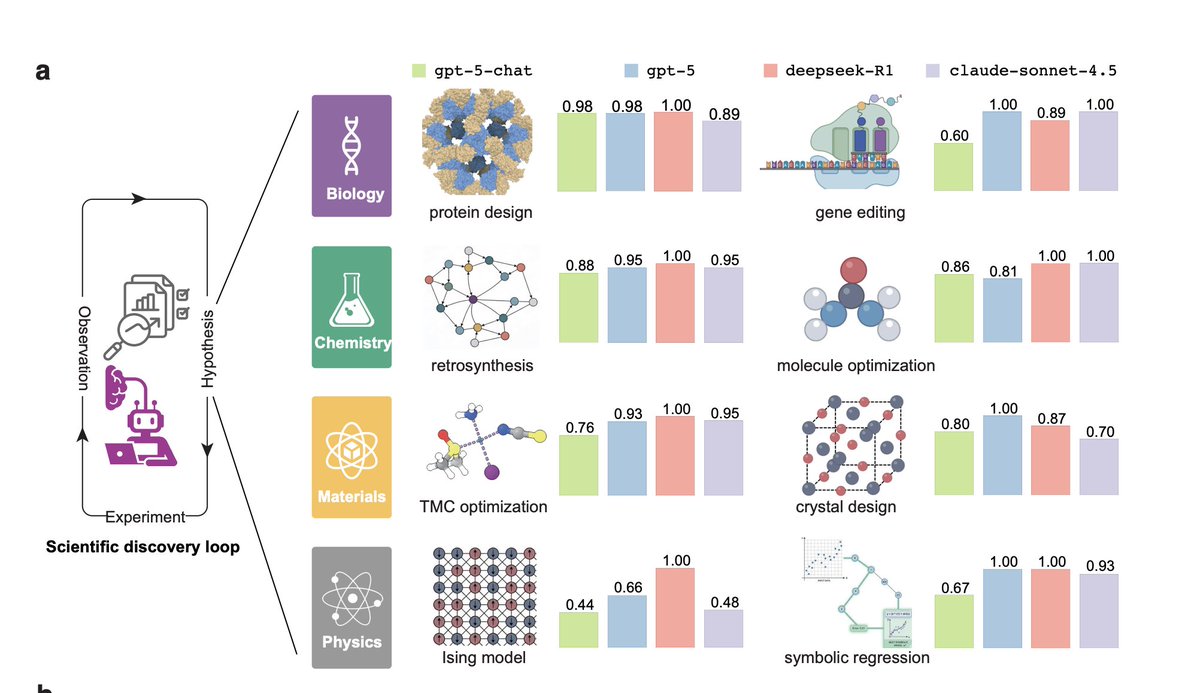
A major failure mode: Models latch onto correlations and invent causal stories. Even when experiments explicitly break the link, the explanation doesn’t change. Fluency replaces falsification.
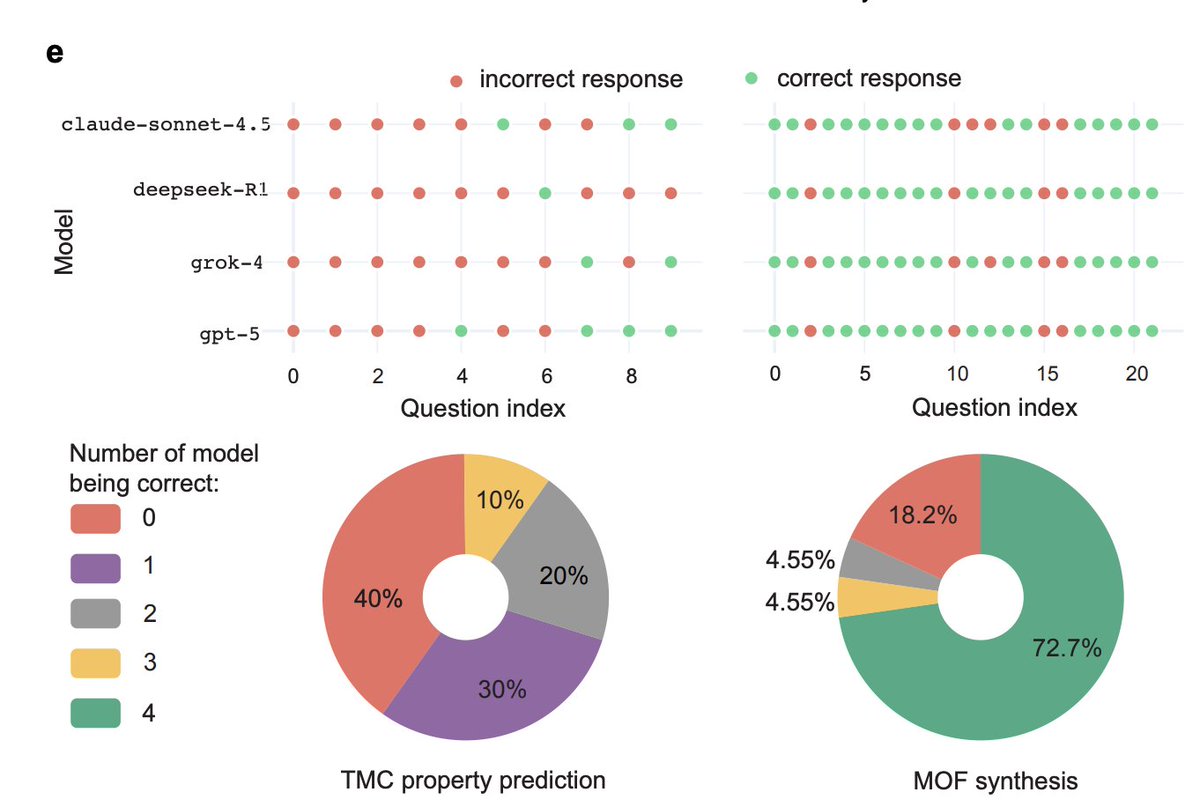
Here’s the uncomfortable result: High scores on standard reasoning benchmarks ≠ High scores on scientific discovery tasks The correlation is weak or nonexistent.

LLMs can talk science. They can’t yet: • Track hypotheses over time • Revise beliefs reliably • Learn from failed experiments Scientific intelligence is iterative, not eloquent. Until models learn that, “AI scientist” is still a metaphor. Read full paper here:
AI prompts your competitors don't want you to find → Prompts for marketing, sales, operations → Unlimited custom prompts → Pay once, own forever Grab it today 👇
the day they find out how to make them think and discover new science; we will get AGI.
yess, so many teams from around the globe collaborated
yes
10x your prompting skills with my prompt engineering guide → Mini-course → Free resources → Tips & tricks Grab it while it's free ↓