
HW's Atlas 950/960 SuperPoD are truly innovative products. It offsets China's disadvantage in advanced node chip fabrication by increasing memory, optimizing for FP4/8 & building large super node using HW's networking expertise. More smaller AI die connected like it's all in 1.

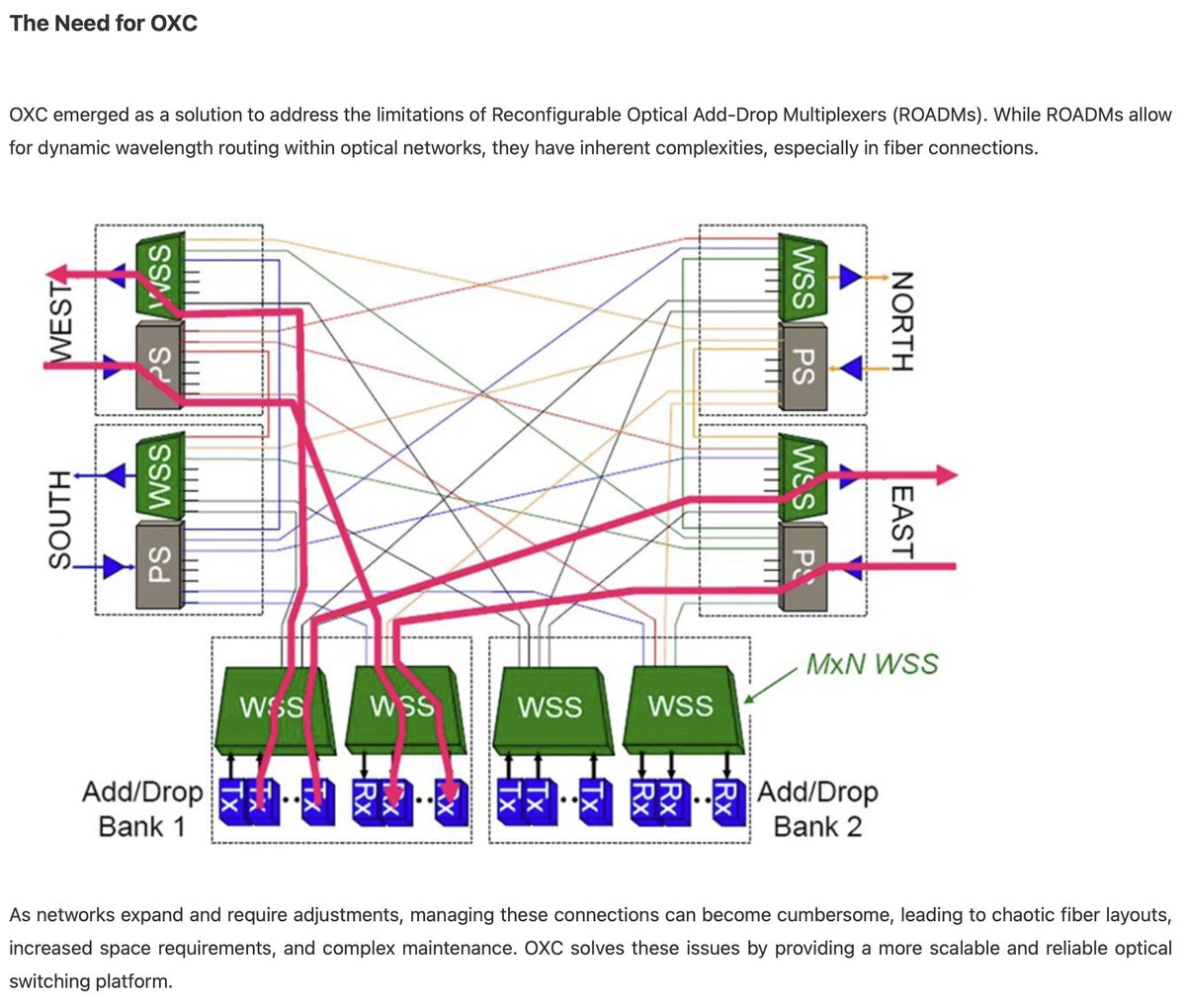
HW utilizes an all optical network built w/ OCS (optical circuit switch). OCS is not new. Google built super nodes w/ 4096 TPUs. HW tries to scale up this further w/ OXC (optical cross connect) to address limitation of increasing complex web of connections as # of nodes grow.
OCS comes in different forms, but the most common one is OCS MEMS using mirrors (see diagram below). HW uses MEMS OCS. Supply chain includes SiPo chips, OCS core, MEMs mirror, InP/GaA wafers, optical modules & various analog + power chip producers + fiber cables.


While 7 of top 10 optical transceiver suppliers last yr were Chinese, HW is entirely vertically integrated & is itself #4 on the list. HW website shows it supplies different optical module pkging including QSFP, CFP, XFP & SFP for different scenarios. It has a lot of experience


So what benefit does OCS have offer traditional routers & switches? It shows 1000ns improved latency, 30% lower cost, 50% improved reliability & 90% lower power consumption. That's probably why everyone is moving in this direction. But what about OXC?

Last yr, HW unveiled the game changing OptiXtrans DC808 (aka DC-OXC) for large DCs. HW claimed it provides 256 ports & allows clusters to scale to millions of cards in on-demand manner & fully supports optical evolution from 200G & 1.6T. Reduces network latency by 20-30+% w/ 0


HW's DC-OXC: OXC Matrix: heart of OXC allowing any internal ports to interconnect. Replacing traditional internal fiber connections / optical backplane (PCB of optical fibers, supporting large switching capacities w/ min delays) Any surprise HW is good w/ complex switches?

See Atlas-950/960 SuperNode using UB switch & OCS interconnect. Single UB switch interconnects bw racks, supporting linear expansion from 64 to 8192 cards. To further expand network scale, it also supports multi-level UB switch expansion (I assume that's where cluster comes in)

When HW unveiled DC-OXC, it claimed huge savings across the board as well as vastly reduced latency as network toplogy becomes flatter. AI chips get higher utilization since less time spent waiting on HBMs & network layers. Great for training, aims to satisfy 10T+ param models


In HW's Atlas-960 presentation, it was the realization of DC-OXC. Each node is 15k+ & 64 nodes per cluster -> almost 1m cards. 36% lower static latency, 43% higher MTBF, 16% fewer switches & 25% fewer optical modules -> less downtime & wait time for NPUs + lower overall cost

Nvidia is only able to put 72 or 144 cards in a SuperNode. HW is able to fit in 15488. Each Atlas-960 can do 30 EFLOPS compute w/ 34 PB/s of total interconnect bandwidth tuned perfectly w/ Longsight network tester. There is no hardware or compute constraint facing Atlas users.
Nobody builds DC w/ just 1 or 2 cards. They need to build huge data center clusters. It's pointless to compare @ card level. AI DCs need to be compared at system level. Once Ascend's s/w supports all the features that AI labs need, there will be no issue using it for training.
Weibo rumor on what Jensen said about HW privately: Says Ascend-910C in high load is only 8-12% slower than H100 (I assume for inference). HW can produce 200k chips per month. While HW did get 3m Ascend dies from TSMC last yr, looks like the domestic production also ramped up.

@tphuang PHB is deeping to the hell?
@tphuang @threadreaderapp unroll
@tphuang For lay readers, the Atlas series is Huawei's line of AI accelerators (Neural Processing Units or NPUs)—a pre-integrated, rack-scale cluster optimized for high-performance computing (HPC). The big Atlas 960 SuperPoD scales to 15,488 NPUs, pushing toward 2 FP8 zettaFLOPS
I am old enough to remember when energy access was considered a key disadvantage for China. This wasn't even controversial: Beijing itself long recognized energy as its key developmental (and geopolitical) bottleneck. Flipping it from a disadvantage to an emerging advantage is
🇨🇳 The official Douyin account of the PLA posted these and they go unreasonably hard



🚨🇨🇳China unveils first-ever thorium-powered cargo ship This cargo vessel powered by a thorium molten salt reactor, capable of carrying 14,000 containers, South China Morning Post reports.

In 2000, China accounted for 6% of global manufacturing. In 2030, China is projected to account for 45% of global manufacturing. The speed and scale of China's industrialization and modernization are unprecedented in human history.
